Computer vision
-

Google launches Gemini, its most advanced AI model
On December 6, 2023, Google launched Gemini, a cutting-edge multimodal AI model that…
-

LCM-LoRA speeds up text-to-image generation with Stable Diffusion models
LCM-LoRA is a universal Stable Diffusion acceleration module that can speed up the…
-

4K4D uses AI to create high-fidelity 4D views of dynamic scenes
4K4D is a new AI method for generating high-quality and real-time images of…
-

PIXART-α: 10x faster text-to-image diffusion model with state-of-the-art results
PIXART-α is a new text-to-image (T2I) diffusion model based on the transformer architecture…
-

PoseDiffusion: a novel diffusion framework for camera pose estimation with epipolar geometry constraints
PoseDiffusion is a new method for camera pose estimation, which means finding the…
-

New AI model reconstructs 3D scenes from eye reflections
A research team from the University of Maryland, College Park proposed an AI…
-

TryOnDiffusion: try on virtual clothes with the power of two UNets
TryOnDiffusion is a new method that leverages diffusion models and cross attention mechanisms to…
-

Adobe, Stanford & Berkeley released a new model for realistically human insertion into scenes
A research team from Adobe, Stanford, and Berkeley unveiled a new large-scale generative…
-

NeRF-Supervised, a novel technique for training stereo models
Google introduced NeRF-Supervised, a new framework for training deep stereo networks without requiring any…
-
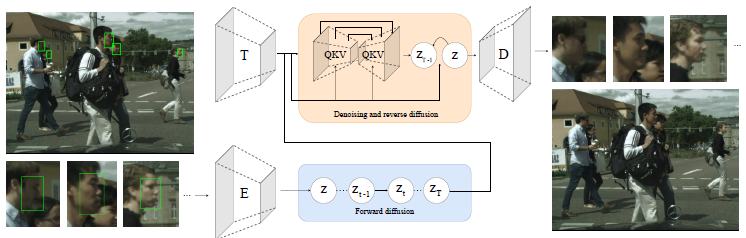
LDFA: Latent Diffusion Face Anonymization for self-driving applications
A new approach called LDFA (Latent Diffusion Face Anonymization) was recently developed by…