Generative
-

FreeU: a simple method to boost diffusion model’s performance with no extra cost
FreeU is a new technique to improve the quality of images and videos…
-

Thousands of free and open audiobooks using synthetic speech from Project Gutenberg, Microsoft, and MIT
A research team from Project Gutenberg, Microsoft, and MIT has developed a system…
-

Ernie Bot, Baidu’s generative AI tool that rivals ChatGPT, is now open to the public
Baidu, one of China’s leading AI companies, has made its large language model, Ernie…
-

Word-As-Image for Semantic Typography (SIGGRAPGH 2023 technical paper awards)
Word-As-Image is a novel and creative way to make semantic typography, where the letters…
-

GestureDiffuCLIP: Gesture Diffusion Model with CLIP Latents (SIGGRAPH 2023 technical paper awards)
GestureDiffuClip is a new framework that can create realistic and expressive body movements…
-

TokenFlow: make high-quality video edits from text prompts using diffusion features
TokenFlow is a framework for text-based video editing that leverages a pre-trained text-to-image…
-
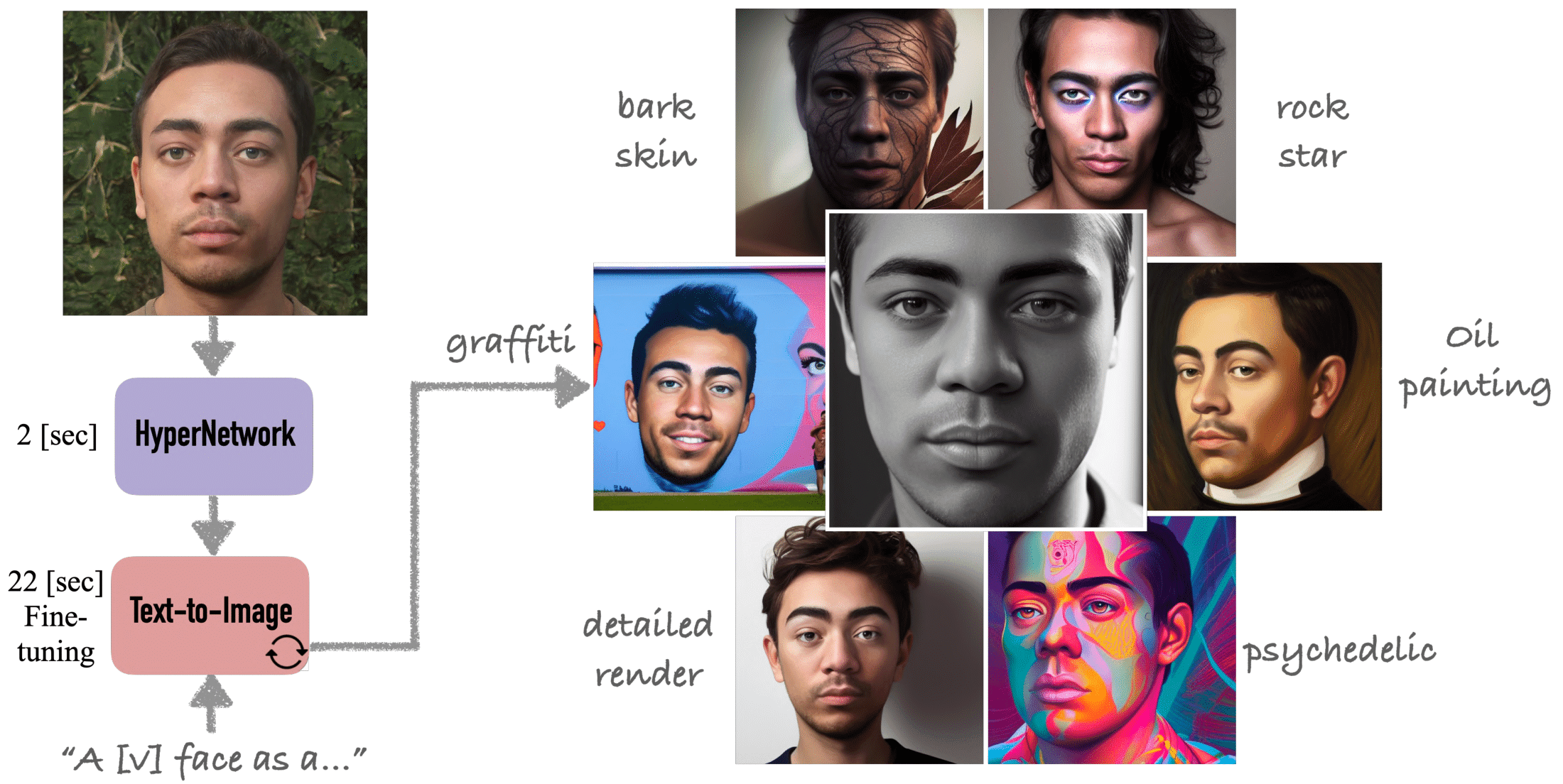
HyperDreamBooth: 25x faster text-to-image personalization with HyperNetworks
HyperDreamBooth is a new powerful method that can generate a person’s face in…
-

SDXL: the next generation of Stable Diffusion models for text-to-image synthesis
Stable Diffusion XL (SDXL) is the latest text-to-image generation model developed by Stability AI, based…
-

TryOnDiffusion: try on virtual clothes with the power of two UNets
TryOnDiffusion is a new method that leverages diffusion models and cross attention mechanisms to…
-

Meta’s open source MUSICGEN: a single language model to create high-quality music from text or melody
Meta proposes MUSICGEN, a simple and controllable tool that generates high-quality music at…