
Grounding DINO 1.5 is a series of powerful open-set object detection models capable of identifying new objects it hasn’t seen before, in addition to objects it has been trained on.
The suite includes two variants designed for different operational environments:
- Grounding DINO 1.5 Pro, created for high performance and strong generalization across diverse detection scenarios. This makes it suitable for applications that require extensive data analysis, such as urban traffic systems, advanced security infrastructure, and sophisticated robotics.
- Grounding DINO 1.5 Edge, optimized for efficiency and faster speed. It can be deployed on edge devices, making it suitable for applications such as autonomous driving or medical image processing.
Grounding DINO 1.5 is an open-source project available under the Apache-2.0 license. You can find the API and usage examples on its GitHub repository. Additionally, a demo enables you to test its capabilities without requiring any installation.
Currently, the model can only be used through the API. There is no plan to release the model weights. The team may provide some fine-tuning or deploy service on their platform in the future (source: GitHub issue #12).
Grounding DINO 1.5
Grounding DINO 1.5 builds upon the dual-encoder-single-decoder architecture of Grounding DINO. This means the model uses two distinct encoders to analyze both visual and textual data simultaneously (see the picture below).
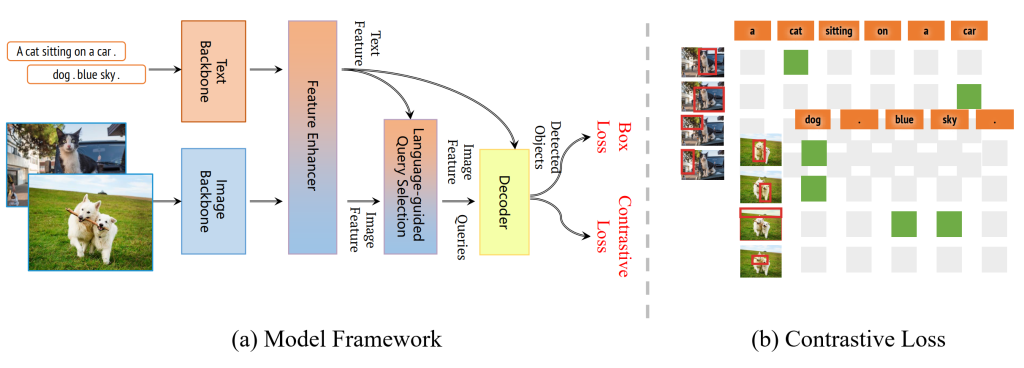
The image backbone processes the input image and extracts the image features. Simultaneously, the text backbone analyzes the input text and extracts the text features.
The feature enhancer subsequently integrates these visual and textual features, forming a multi-modal feature space used by the decoder to identify and locate objects. This methodology ensures that the model not only detects objects but also understands their context within the image.
Loss Functions, which are used by the optimizer during training, include the Box Loss (for object detection accuracy) and Contrastive Loss (to ensure the alignment between text and image features). Contrastive Loss, as illustrated in image (b), guarantees precise alignment between the relevant text and image features within the model. For example, features of “a cat sitting on a car” should be closely linked with the specific image section displaying the cat on the vehicle, whereas features of unrelated text, like “dog” or “blue sky,” should not correspond with the image features of the cat.
The training dataset for Grounding DINO 1.5 is a comprehensive collection called Grounding-20M, with over 20M images from public domains, covering various detection scenarios.
In the next two chapters we’ll examine the two variants of DINO 1.5: Pro and Edge.
Grounding DINO 1.5 Pro
Grounding DINO 1.5 Pro maintains the essential architecture of its predecessor, with the following features and improvements:
- Use a larger Vision Transformer backbone (ViT-L), enabling more detailed scene analysis.
- Perform a deep early fusion during the feature extraction phase, following the methodologies of Grounding DINO and GLIP. This process allows for the concurrent examination of both visual and textual data, leading to a better understanding of the scene.
- Train with more negative samples (images lacking the target objects) to avoid hallucinations that can arise from early fusion.
Grounding DINO 1.5 Edge
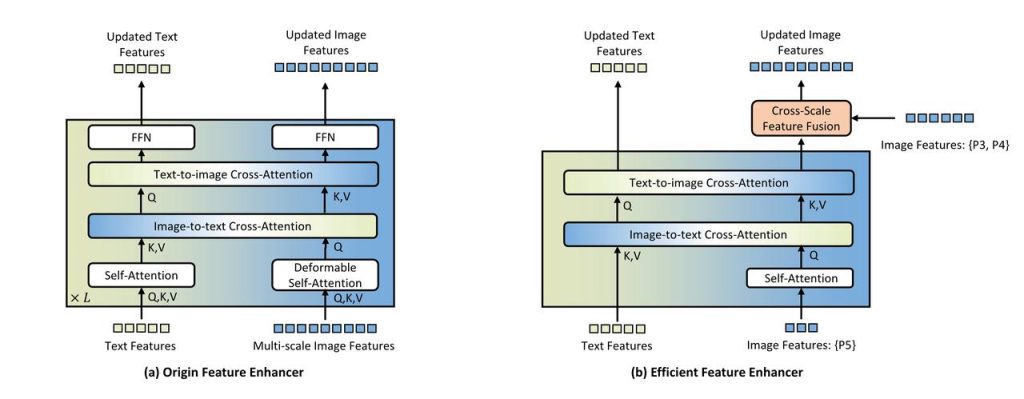
The Grounding DINO 1.5 Edge model is designed for devices with limited computing capabilities. The initial Grounding DINO version uses multi-scale image features and a computationally intensive feature enhancer, which are not suited for real-time applications in everyday scenarios. To reduce the computational load, the developers suggest several modifications to the model:
- Use a new efficient feature enhancer that focuses only on high-level features (P5 level). This reduces the number of tokens to be processed and, consequently, the computational load (see the picture below).
- Simplify the attention mechanism by replacing the complex deformable self-attention with a simpler vanilla self-attention model.
- Introduce cross-scale feature fusion to integrate lower-level image features (from P3 and P4 levels) without the high computational cost.
Evaluation
Grounding DINO 1.5 Pro was tested for its ability to detect and correctly classify objects in images in both scenarios: zero-shot and fine-tuning.
Zero-Shot Transfer of Grounding DINO 1.5 Pro: in these scenarios the model encounters objects it has not been explicitly trained to recognize on (see the next figure).
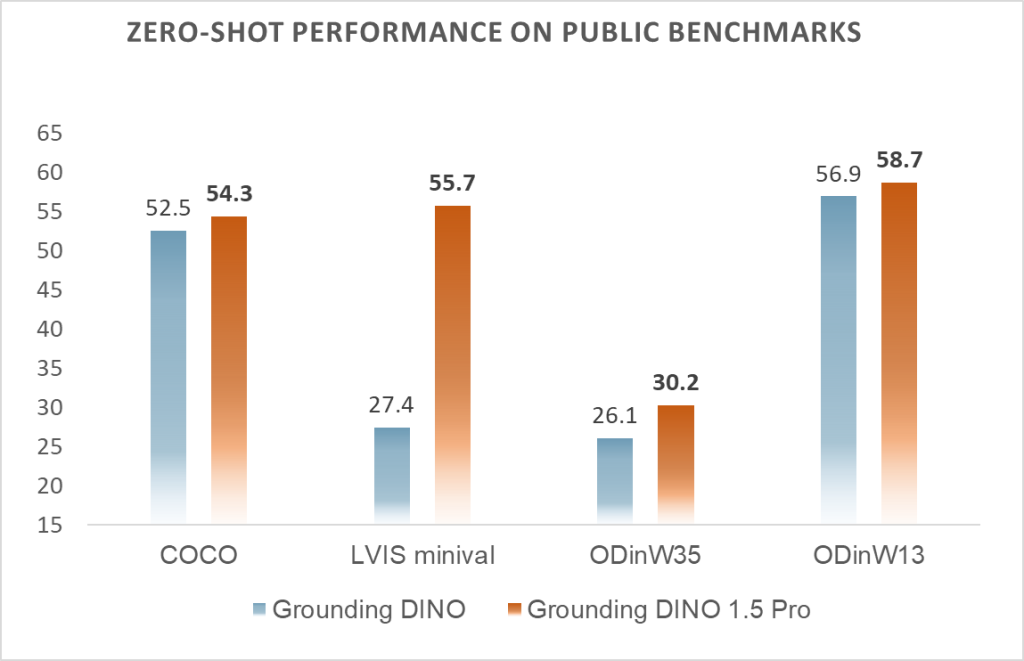
Grounding DINO 1.5 Pro exhibits impressive zero-shot transfer capabilities across a range of benchmarks (COCO, LVIS, ODinW35, and ODinW13), outperforming previous methods.
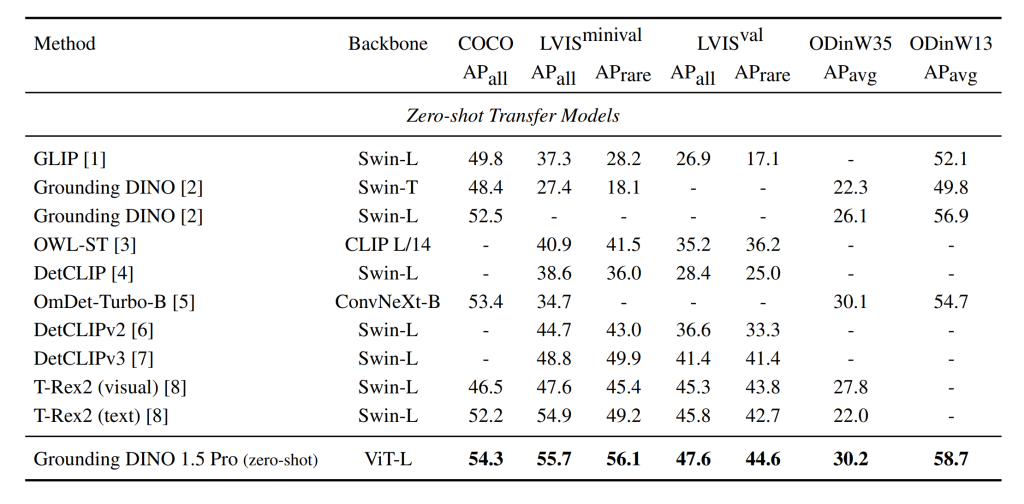
Fine-tuning Results on Downstream Datasets: fine-tuning Grounding DINO 1.5 significantly improves its performance.
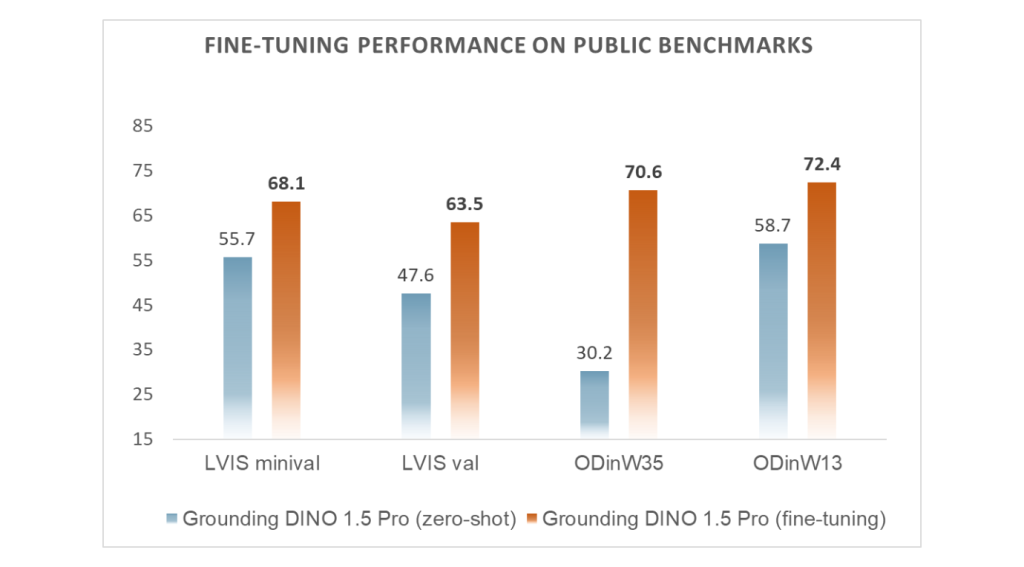
As shown in the table below, on the LVIS dataset, the model achieves a significant jump in accuracy (by 12.4 and 15.9 AP) on both LVIS-minival (68.1 AP) and LVIS-val (63.5 AP) datasets compared to its base performance. Grounding DINO 1.5 also sets new benchmarks on the ODinW35 benchmark, achieving an impressive 70.6 AP across 35 datasets and 72.4 AP on 13 datasets.

Grounding DINO 1.5 Edge was tested on the COCO and LVIS datasets. It achieves a zero-shot AP score of 45.0 on the COCO benchmark. On the LVIS-minival benchmark, it outperforms all other methods with a score of 36.2 AP. The model is also fast. When optimized for NVIDIA hardware, it achieves an inference speed of over 10 frames per second with a resolution of 640×640 pixels.
Conclusion
Grounding DINO 1.5 is a new step in the area of open-set object detection models. With its dual-encoder-single-decoder architecture, enhanced multi-modal integration, and advanced loss functions, it is capable of performing detection
across a wide range of real-world applications, outperforming the existent models.
Learn more:
- Paper on arXiv: “Grounding DINO 1.5: Advance the “Edge” of Open-Set Object Detection”
- GitHub repository
- Project page
- Demo






