
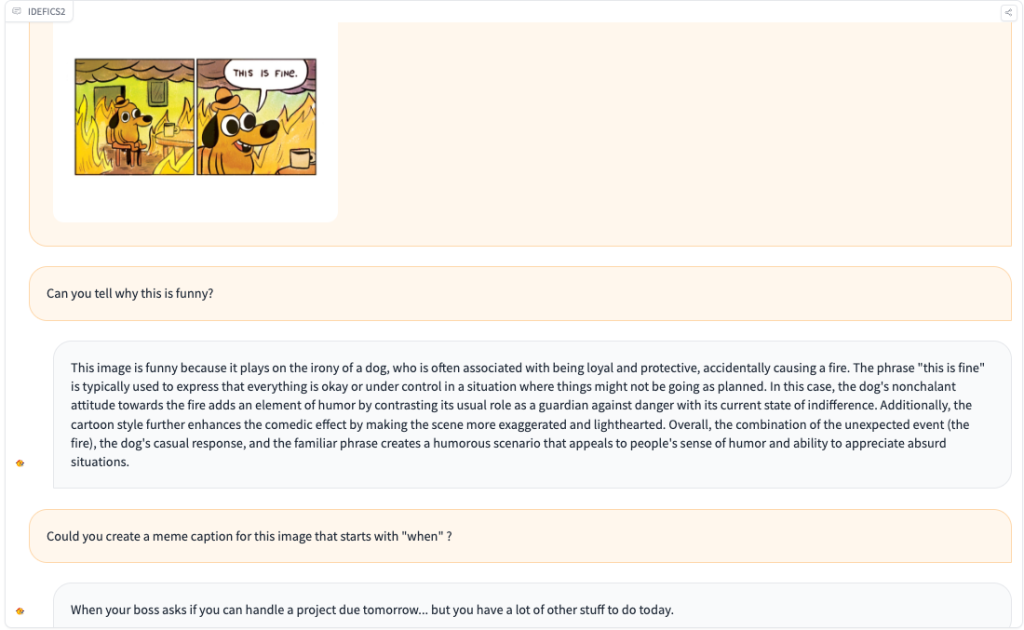
Hugging Face has launched Idefics2, an 8B parameters multimodal model that rivals the capabilities of significantly larger models like LLava-Next-34B and MM1-30B-chat. The model can handle combinations of texts and images as inputs to create text-based outputs.
Idefics2 is able to answer questions about images, describe visual content, create stories based on multiple images, retrieve information from documents, and carry out simple math calculations.
The model is released under the Apache 2.0 license and can be accessed here. Idefics2 is available on the Hugging Face Hub and they also provide a fine-tuning colab for specific use cases.
Capabilities
Idefics2 accepts multiple image and text inputs and can answer questions about images, describe visual content, or create stories based on multiple images. The model can handle different image ratios up to 980 x 980 pixels without resizing. Its training data includes tasks that require answering questions on charts, figures, and documents, which improves its visual reasoning abilities. Idefics2 has better OCR capabilities and can transcribe text from images or documents.
Idefics models
Idefics (Image-aware Decoder Enhanced à la Flamingo with Interleaved Cross-attentionS) is an open-access multimodal visual language model that can process and understand sequences of images and texts, generating coherent text outputs. It is inspired by Flamingo and matches the performance of the original proprietary model in numerous image-text comprehension tests. The model is available in two versions: one with 80B parameters and another one with 9B parameters.
Idefics is constructed exclusively using data and models that are accessible to the public, specifically LLaMA v1 and OpenCLIP.
Idefics2: improvements over Idefics1
Even though it’s 10 times smaller than Idefics1, Idefics2 offers a substantial performance improvement. Here are the key improvements:
- Idefics2 processes images at their original resolution (up to 980 x 980) and maintains their aspect ratios using the NaViT strategy. This eliminates the need to resize images into fixed-size squares, as required in computer vision. Additionally, the SPHINX strategy is used, allowing optional subdivision of images and processing of extremely high-resolution images.
- The Optical Character Recognition (OCR) capabilities have been improved by incorporating data that requires extracting text from images or documents. The model’s ability to answer questions about charts, graphs, and documents has also been improved through specialized training data.
- Idefics2 simplifies image processing: unlike Idefics1’s complex approach, Idefics2 employs a simpler method to integrate visual features with text (see the picture below).
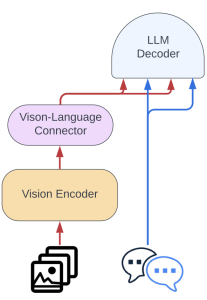
First, the images are fed to a vision encoder. Next, the encoded images are connected with language through a vision-language connector. Finally, the combined image-text sequence is decoded with an LLM decoder to produce relevant outputs. This allows the model to effectively process and generate responses based on both visual and textual data.
Training data
Idefics2 was trained on a combination of publicly available datasets, including web documents from Wikipedia and OBELICS, image-caption pairs from Public Multimodal Dataset and LAION-COCO, OCR data from PDFA (en), IDL, Rendered-text, and image-to-code data from WebSight. An interactive visualization feature is available for exploring the OBELICS dataset.
The base model was further fine-tuned on task-oriented data. Given that such data frequently come in different formats and scattered across various sources, the team introduced The Cauldron, a carefully selected collection of 50 datasets organized for multi-turn dialogues. Idefics2 was fine-tuned on the combined dataset of The Cauldron and various text-only instructions fine-tuning datasets.
Evaluation
Idefics2 was evaluated on different benchmarks and compared with state-of-the-art models. The results can be seen in the picture below.
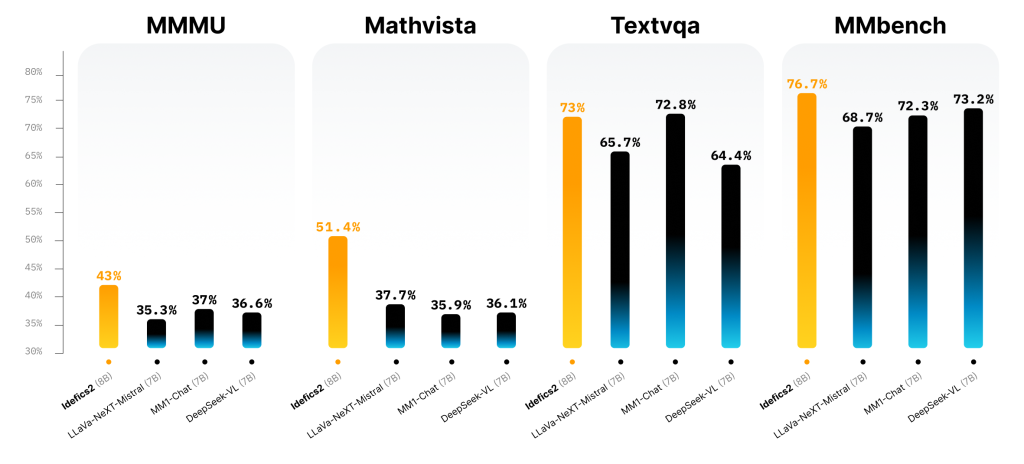
In Visual Question Answering benchmarks, its performance ranks at the forefront of its size category, and it holds its own against significantly larger models like LLava-Next-34B and MM1-30B-chat.
Conclusion
The release of Idefics2’s ability to seamlessly integrate textual and visual information unlocks a deeper understanding of the world.
Idefics2 builds upon its predecessor with several enhancements. It handles images at native resolutions, incorporates improved OCR for text extraction, and uses a streamlined approach for integrating visual features with text.






