
LLMLingua-2 is a new method for prompt compression in Large Language Models. It employs the data distillation technique to extract key information and condense prompts, while preserving essential details.
LLMLingua-2, which was proposed by a research team from Tsinghua University and Microsoft Corporation, is 3x–6x faster than the existing methods. Additionally, it is designed to be task-agnostic, showcasing strong adaptability and generalization across various Large Language Models (LLMs).
It is part of the LLMLingua series, which focuses on prompt compression (see the picture below). The model is open source, allowing you to access the code and you can try its demo here.
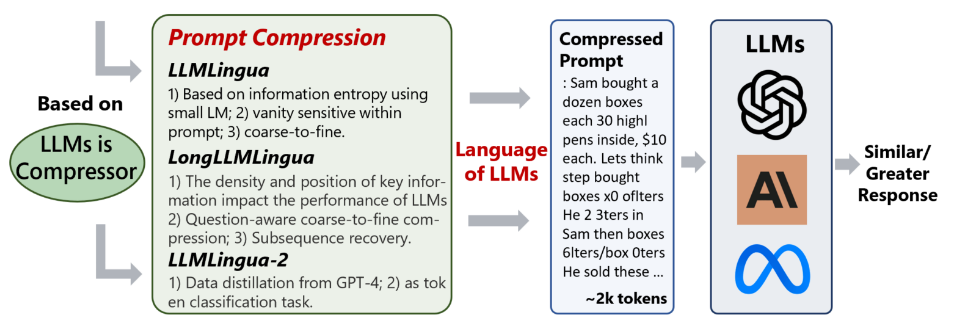
Prompting techniques
Prompting techniques like Chain of Thought (COT), In-Context Learning (ICL), and Retrieval-Augmented Generation (RAG) are designed to improve LLMs’ performance. Yet, their reliance on extensive prompts results in greater computational requirements and high financial costs.
Prompt compression addresses the issue of long prompts by removing unnecessary information. Yet, its effectiveness may differ depending on the specific methods employed:
- Information Entropy identifies and removes redundant parts of a prompt, though it might not consistently discern the critical information necessary for the task.
- Causal Language Models (CLMs) analyze text in a sequential manner, from left to right, which can lead to overlooking intricate inter-word relationships.
- Data distillation, the innovative method of LLMLingua-2. This technique does not customize prompts for particular tasks; instead, it concentrates on compressing the overall information in a task-agnostic manner.
Model overview
The next figure illustrates the model overview, detailing the data construction process (steps 1–3) and prompt compression procedures (steps 4 & 5).
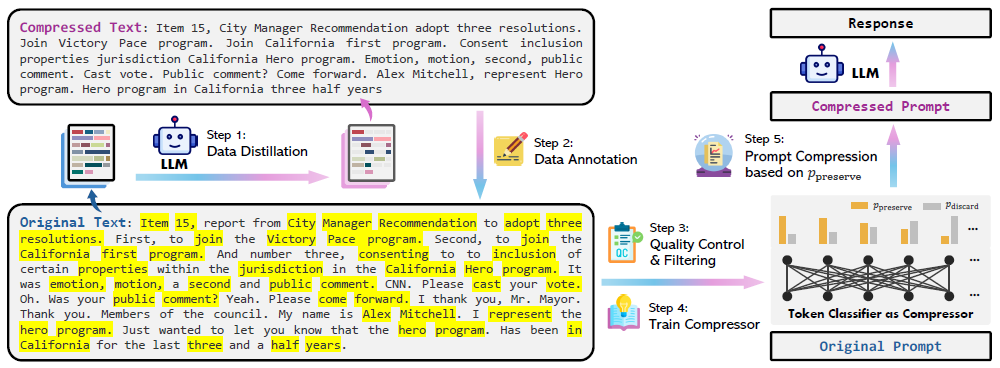
LLMLingua-2 is trained to distill the essential meaning from texts, allowing the LLM to function effectively with compressed inputs. The model’s training involved a specialized dataset from MeetingBank, consisting of text pairs with the original transcripts and their compressed versions.
Step 1. Data distillation
The picture below shows the instruction used for data distillation:

Steps 2 & 3. Data annotation, quality control and filtering
Data annotation categorizes each token in the original texts with a binary label, indicating whether it should be kept or removed post-compression. The process of data annotation encounters several challenges (see the picture below):
- Ambiguity: in the compressed text, a single word may correspond to multiple occurrences in the original content.
- Variation: during the compression process, GPT-4 might alter the form of the original words, such as changing tenses or number (singular to plural, etc.).
- Reordering: the sequence of words in the original text might be rearranged in the compressed version.

Steps 4 & 5. Train compressor and prompt compression
The model uses a transformer encoder to analyze the context of prompts bidirectionally and identify important information for compression. Subsequently, a trained linear classification layer assigns a probability score to each token in the prompt. Finally, the model decides whether to retain or discard the token based on the probability scores.
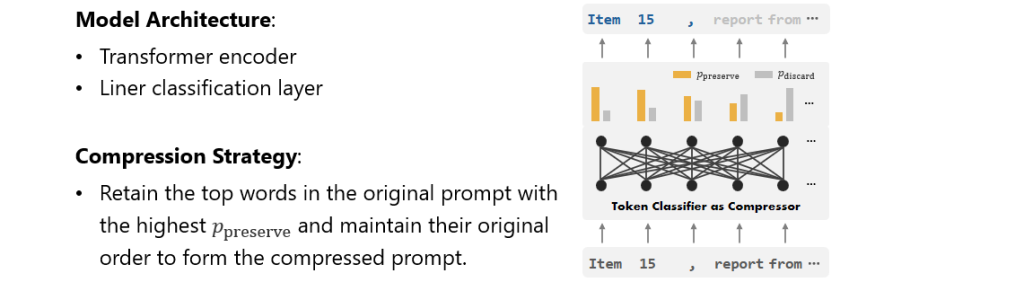
The tokens’ scores range from 0 to 1. Tokens with scores approaching 1 are generally retained, whereas those with scores nearing 0 are likely to be excluded.
LLMLingua-2 was developed using HuggingFace’s Transformers and PyTorch 2.0.1 with CUDA-11.7. The training process took approximately 23 hours on the MeetingBank compression dataset. Two encoder options were used: xlm-roberta-large for LLMLingua-2 and multilingual-BERT for LLMLingua-2-small.
Evaluation
The model has been evaluated using a range of datasets, including those closely related to its training environment, like MeetingBank, and others that extend beyond its primary domain, such as LongBench, ZeroScrolls, GSM8K, and BBH.
The evaluation encompassed a diverse array of tasks, such as in-context learning, summarization, conversation, multi-document QA, single-document QA, code, and synthetic tasks.
The table below showcases the result of in-domain evaluation of different methods on the MeetingBank dataset. Additional evaluation results are available on the project page.

Despite its smaller size compared to previous models, LLMLingua-2 demonstrates significant performance over strong baselines. It shows robust generalization ability across different LLMs, from GPT-3.5-Turbo to Mistral-7B. Moreover, it is 3 to 6 times faster than current prompt compression techniques, reducing the overall response time by a factor of 1.6 to 2.9 with compression ratios of 2 to 5 times.
Case study
The picture below showcases an online meeting question answering task.
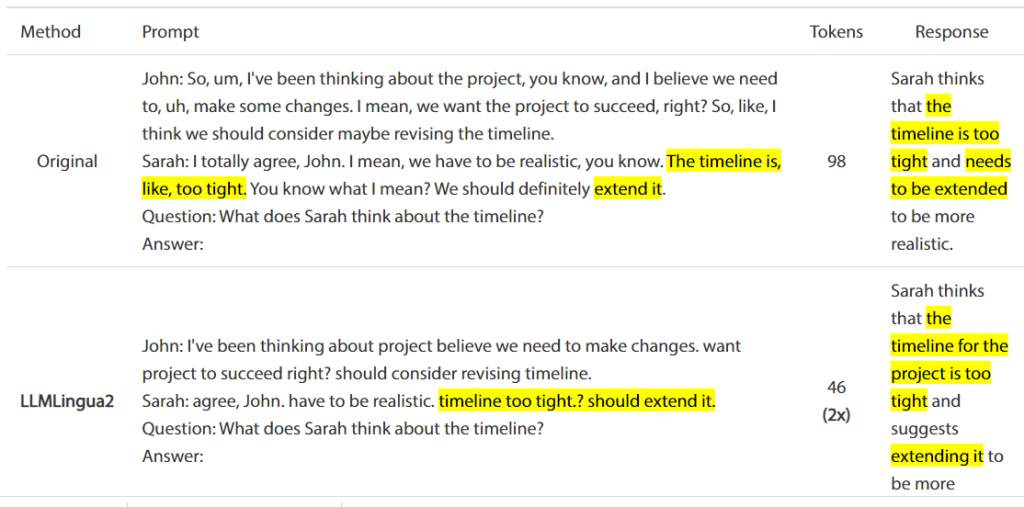
The online meetings often involve redundant information and lengthy prompts. By compressing these prompts, LLMLingua-2 effectively reduces latency, leading to faster and smoother AI responses.
Conclusion
LLMLingua is a new framework for prompt compression that allows you to achieve similar results with shorter prompts, leading to significant speed improvements.
Its ability to efficiently compress prompts without sacrificing fidelity opens new ways for more responsive and user-friendly LLMs. As the demand for real-time NLP applications grows, techniques like LLMLingua-2 will become increasingly important in delivering the performance users expect.






