
StreamDiffusion is a new diffusion pipeline specifically tailored for real-time image generation. It delivers high speed and efficiency, enabling seamless integration into applications that demand continuous input, such as real-time game graphics rendering, generative camera filters, real-time face conversion, and AI-assisted drawing.
The project is open-source and can be accessed here.
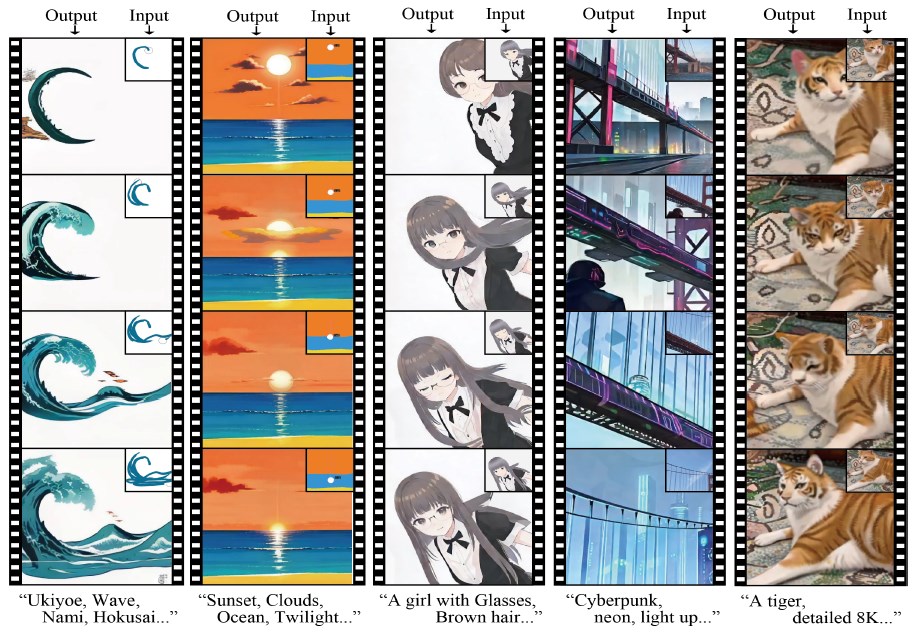
Unlike the conventional diffusion models that denoise image data step by step, StreamDiffusion adopts a batch-based approach inspired by computer architecture. It temporarily stores inputs and outputs in a cache and uses this data when needed. This efficient data management system allows StreamDiffusion to keep pace with real-time demands, enabling uninterrupted and intuitive image generation.
The model
The StreamDiffusion pipeline consists of two main parts, VAE and U-Net, and utilizes caches along with a denoising batch to enhance speed, enabling real-time image generation.
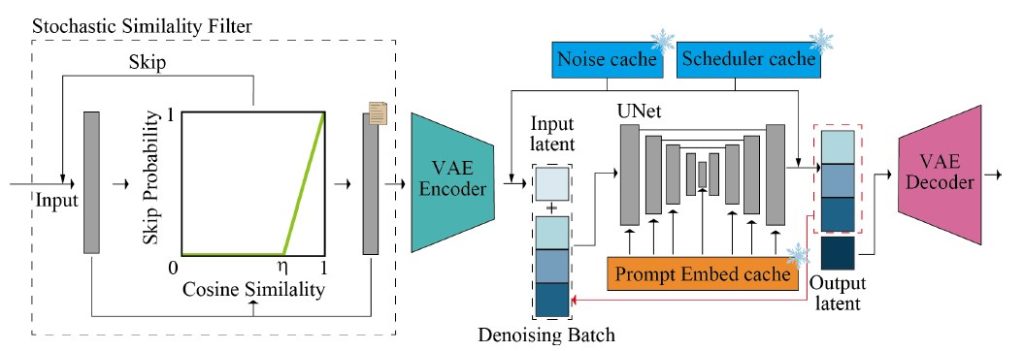
The model employs 6 cutting-edge techniques for both throughput and GPU usage:
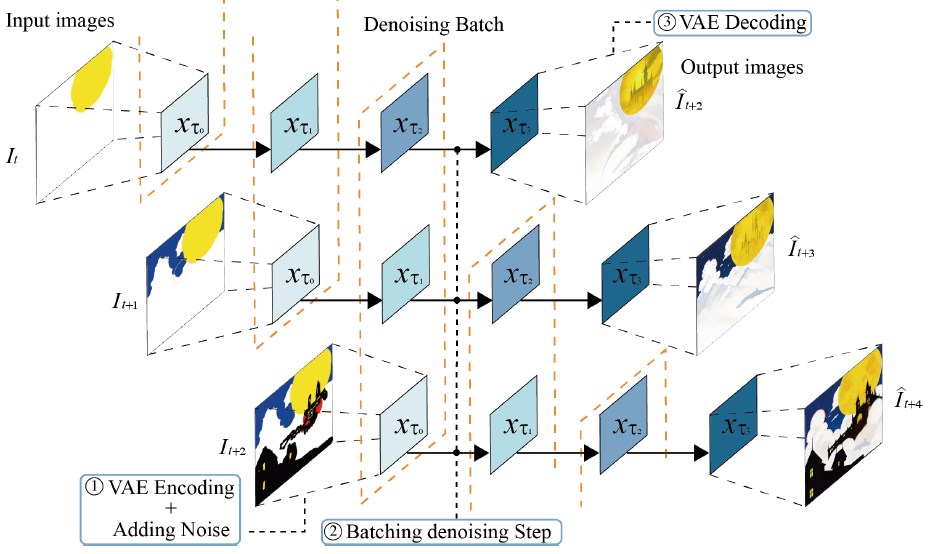
1. Batching the denoising step
It uses a denoising batch and work on many images at the same time. Instead of waiting for a single image to be fully denoised (cleaned) before processing the next input image, the model takes a new image after each step of noise removal, making a batch of denoised images. This denoising strategy enables it to handle continuous input streams (see the next figure).
2. Optimizing the guidance mechanism
The current diffusion pipelines use the classifier-free guidance (CFG) algorithm to match the generated images with the given input prompts. However, CFG has a lot of unnecessary computation. The new algorithm called residual classifier-free guidance (RCFG) works by reducing the number of times the program has to compute the difference between the input image and the output image (the residual). RCFG can reduce the number of residuals to only one or even zero, depending on the quality of the input image.
The paper claims that RCFG can make the image generation up to 2.05 times faster than CFG. Additionally, for a static scene input, RCFG can decrease program energy consumption by up to 2.39 times on an RTX 3060 GPU and 1.99 times on an RTX 4090 GPU.
3. Reducing the input-output queue
The neural network modules, such as VAE (to compress and decompress images) and U-Net (to modify images), are the main slowdown in fast image generation systems. To increase the generation speed, processes like pre-processing and post-processing of images that don’t need handling by the neural network modules are moved outside the pipeline.
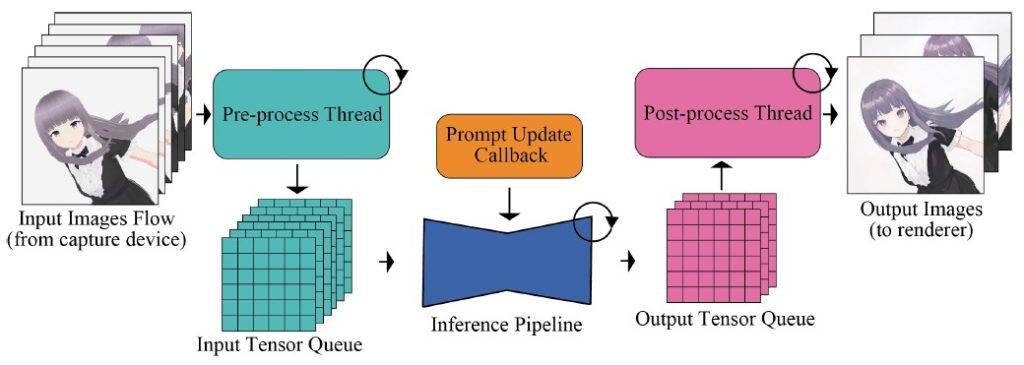
Pre-processing is when the system prepares the images for the models, such as resizing, cropping, or color normalization. Post-processing is when the system improves the images after the models, such as sharpening, smoothing, or enhancing. These are steps that the system can do without using the neural networks, so they can be moved outside of the pipeline and processed in parallel.
4. Stochastic Similarity Filter (SSF)
By using SSF, a technique that compares the input and output images at each denoising step, the system can determine whether to apply the diffusion model or not. This way, the system can save GPU resources by skipping the diffusion model when the images are very similar or identical.
5. Use pre-computed caches
StreamDiffusion caches three things in memory: prompt embeddings of input images, sampled noise, and scheduler values for the diffusion steps. This reduces unnecessary recalculations.
6. Tiny AutoEncoder (TAESD)
To accelerate the decoding process, the system uses a Tiny AutoEncoder for Stable Diffusion (TAESD), instead of the traditional Stable Diffusion AutoEncoder. This lightweight architecture is tailored for image generation, enabling significantly faster decoding without compromising image quality. Additionally, it uses a model acceleration tool to enhance the decoding speed.
Experiments
The combination of these innovative strategies and existing acceleration tools has yielded remarkable performance benchmarks. StreamDiffusion achieves up to 91.07 frames per second (fps) on a single RTX 4090 GPU, surpassing the throughput of AutoPipline developed by Diffusers by an astonishing 59.56x.

StreamDiffusion’s efficiency extends beyond pipeline optimization. It also significantly reduces energy consumption, with reductions of up to 2.39x and 1.99x on RTX 3060 and RTX 4090 GPUs, respectively. This power-saving aspect is particularly beneficial for applications that demand high-performance image generation while prioritizing energy efficiency.
Conclusion
StreamDiffusion represents a significant leap forward in real-time image generation. It leverages innovative techniques like caching and GPU power optimization to achieve high throughput, while reducing energy consumption and computational redundancy.
Learn more:
- Research paper: “StreamDiffusion: A Pipeline-level Solution for Real-time Interactive Generation” (on arXiv)
- Project page






