
Apple Research introduces FastVLM, a new architecture designed to accelerate Vision-Language Models (VLMs) while maintaining strong accuracy. Vision Language Models can understand both images and text, generating responses like image descriptions or answers to visual questions.
Showcased at CVPR 2025, FastVLM features a new hybrid vision encoder, FastViTHD, designed to reduce the number of visual tokens generated during image processing. This enables faster and more efficient handling of high-resolution, text-rich images, achieving a superior balance between speed, accuracy, and computational cost compared to previous VLMs.
The model is fully open-source, with code, model checkpoints, and Apple Silicon deployment tools available under a permissive license.
How FastVLM speeds up vision-language tasks
While powerful, traditional VLMs like GPT-4V and LLaVA are slow and resource-intensive, especially when processing high-resolution, text-rich images. At high resolutions the number of tokens grows substantially and the traditional visual encoders such as Vision Transformers (ViTs) become increasingly inefficient. More tokens lead to greater computational complexity, higher memory consumption, and increased encoding latency. This latency becomes a major bottleneck, particularly in real-time applications or on resource-limited devices such as smartphones.
FastVLM solves this by using a hybrid vision encoder called FastViTHD, which produces fewer, more meaningful visual tokens, thus reducing encoding time and speeds up overall response (see the next picture).
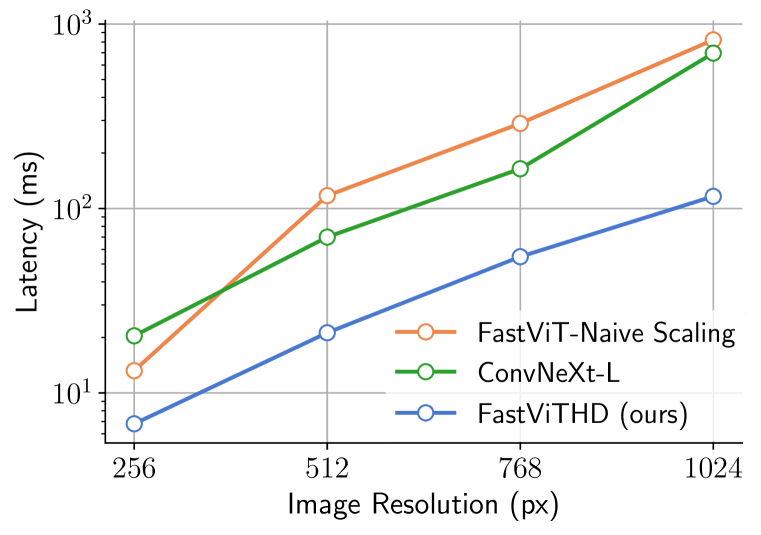
Instead of splitting images into thousands of tokens, FastVLM compresses key information into a small set of compact tokens that a language model (like Qwen2 or Vicuna) can interpret quickly and accurately.
Core advantages
- Lower latency (high speed): FastVLM-0.5B delivers an 85× faster Time-to-First-Token (TTFT) compared to LLaVA-OneVision-0.5B, while achieving comparable performance at the same resolution (1152×1152). Additionally, FastVLM-7B (powered by Qwen2-7B) achieves a 7.9× faster TTFT than Cambrian-1-8B, with similar accuracy.
- Smaller size: The vision encoder in FastVLM-0.5B is approximately 3.4× smaller than that of LLaVA-OneVision-0.5B, making it ideal for on-device use like iPhone, iPad, Mac, running without cloud dependency for enhanced speed and privacy.
- High accuracy: It maintains strong performance on text‑rich, high-resolution benchmarks like DocVQA, SeedBench, and MMMU.
The model
FastVLM comprises three main parts:
- FastViTHD vision encoder: A hybrid vision encoder optimized for high-resolution inputs with low delay (latency). It generates fewer tokens (4× fewer than FastViT and 16× fewer than ViT-L/14 at resolution 336), making it much faster without losing performance.
- Vision-language projector: Aligns the vision encoder’s output tokens with the embedding space of a pretrained LLM, enabling seamless multimodal integration
- LLM decoder: Uses decoder models such as Vicuna 7B or Qwen2 0.5B/7B. Variants based on Qwen2 show strong performance improvements on multimodal benchmarks.
The next diagram illustrates the FastVLM architecture, focusing on its custom vision encoder, FastViTHD, and how it connects to a large language model (LLM) to answer questions based on images.
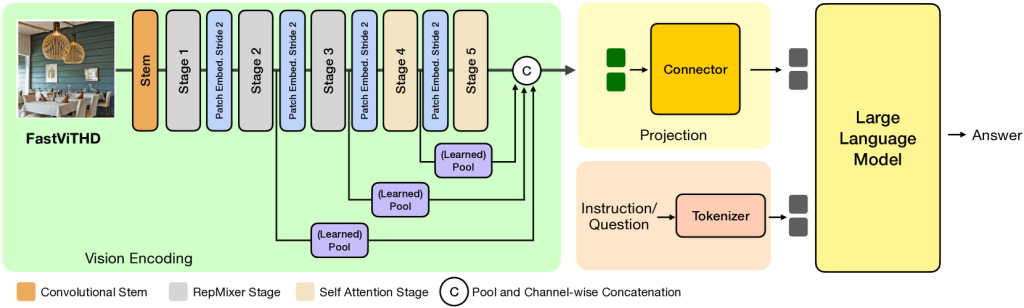
FastViTHD, the hybrid vision encoder in FastVLM, is designed to process high-resolution images efficiently by generating fewer, smarter tokens. It begins with a convolutional layer that extracts low-level features, followed by five stages that progressively reduce the image size and complexity. The key outputs from these stages are passed through learnable pooling layers that summarize important visual information. The result is a compact, rich image representation, which is then mapped into the language model’s embedding space via a lightweight connector. The LLM combines this visual input with text (such as a question) to generate accurate, low-latency responses.
Training
The training setup for FastVLM closely follows the LLaVA-1.5 configuration. It uses a two-stage training approach:
- Stage 1: Train the vision-language projection module while keeping the vision encoder and LLM decoder (e.g., Qwen2 or Vicuna) frozen.
- Stage 2: Fine-tune the entire model, including the vision encoder and LLM.
The authors also explored a three-stage setup, where an additional intermediate step is used to gradually adapt components before full fine-tuning. This variation is included in their released checkpoints and was shown to improve performance in some settings.
All FastVLM models reported in the paper are trained on a single node with 8× NVIDIA H100-80GB GPUs.
Evaluation results
In the LLaVA-1.5 configuration, FastVLM is more than 3× faster than prior work. The next pictures compare popular CLIP-pretrained vision encoders for VLMs using (a) Qwen2 0.5B and (b) Vicuna 7B.
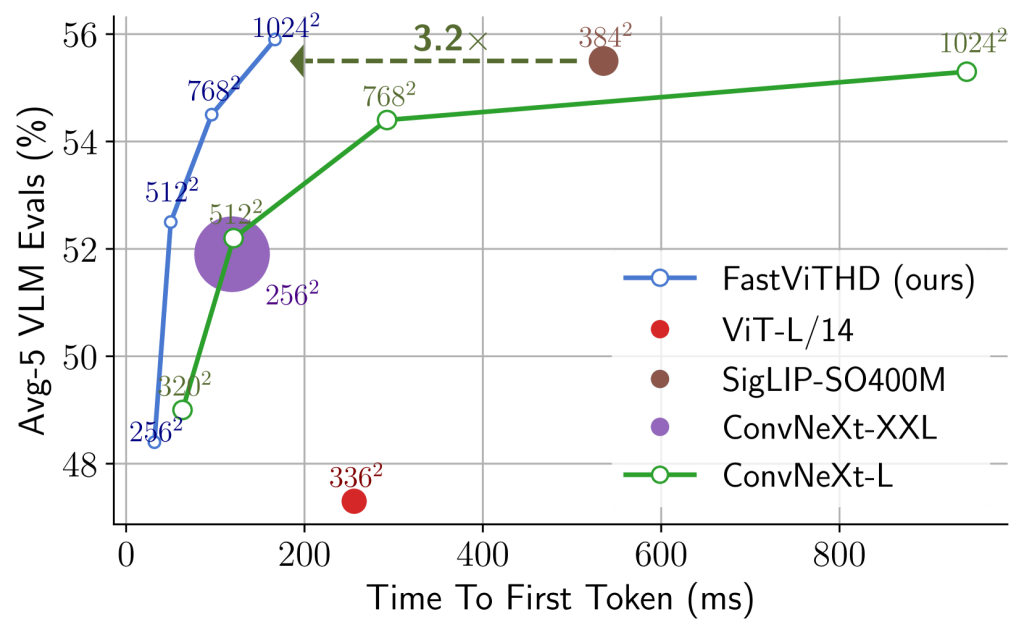
Qwen2 0.5B LLM (source: paper)
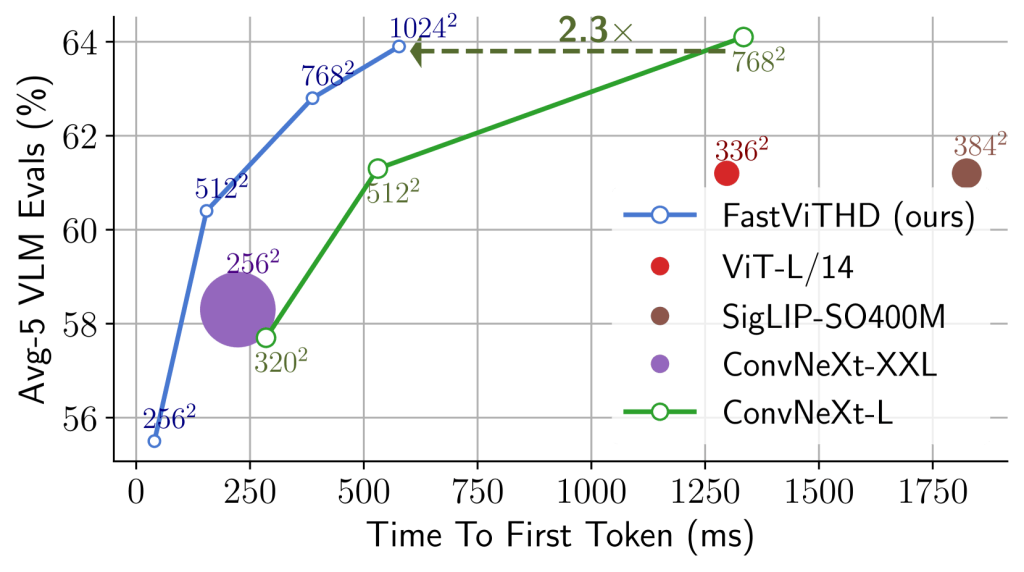
Vicuna 7B LLM (source: paper)
The models are trained with the LLaVA-1.5 setup and all the vision encoders are CLIP pretrained. Marker size shows encoder parameter count, and the x-axis shows total latency (vision encoder + LLM prefilling). All models are benchmarked on an M1 Macbook Pro.
The next table shows that FastViTHD delivers strong performance on CLIP benchmarks at much lower latency.
| Image encoder | Encoder size(M)↓ | Input res. | Latency enc.(ms)↓ | Zero-shot ImageNet | Avg perf. retrieval | Avg perf. on 38 tasks |
| ViT-L/14 | 304 | 224 | 47.2 | 79.2 | 60.8 | 66.3 |
| ViTamin-L | 333 | 224 | 38.1 | 80.8 | 60.3 | 66.7 |
| ConvNeXt-L | 200 | 320 | 34.4 | 76.8 | 64.8 | 63.9 |
| FastViTHD | 125 | 224 | 6.8 | 78.3 | 67.7 | 66.3 |
How to use FastVLM
To get started with the model you have to clone the repo, install dependencies, download models, and run. Advanced users may integrate FastVLM into LLaVA pipelines, perform further finetuning or export optimized ONNX/CoreML targets using provided scripts. For mode details, visit its GitHub repository.
You can use the model for image captioning, visual question answering (VQA), image recognition and analysis.
Conclusion
FastVLM is an open-source, highly efficient Vision-Language Model that addresses the key limitations of traditional VLMs such as high latency and large computational demands, especially when processing high-resolution, text-rich images.
By introducing FastViTHD, a hybrid vision encoder that produces fewer and more informative visual tokens, FastVLM significantly reduces Time-to-First-Token (TTFT). The model is compact and on-device ready, fast and accurate.





