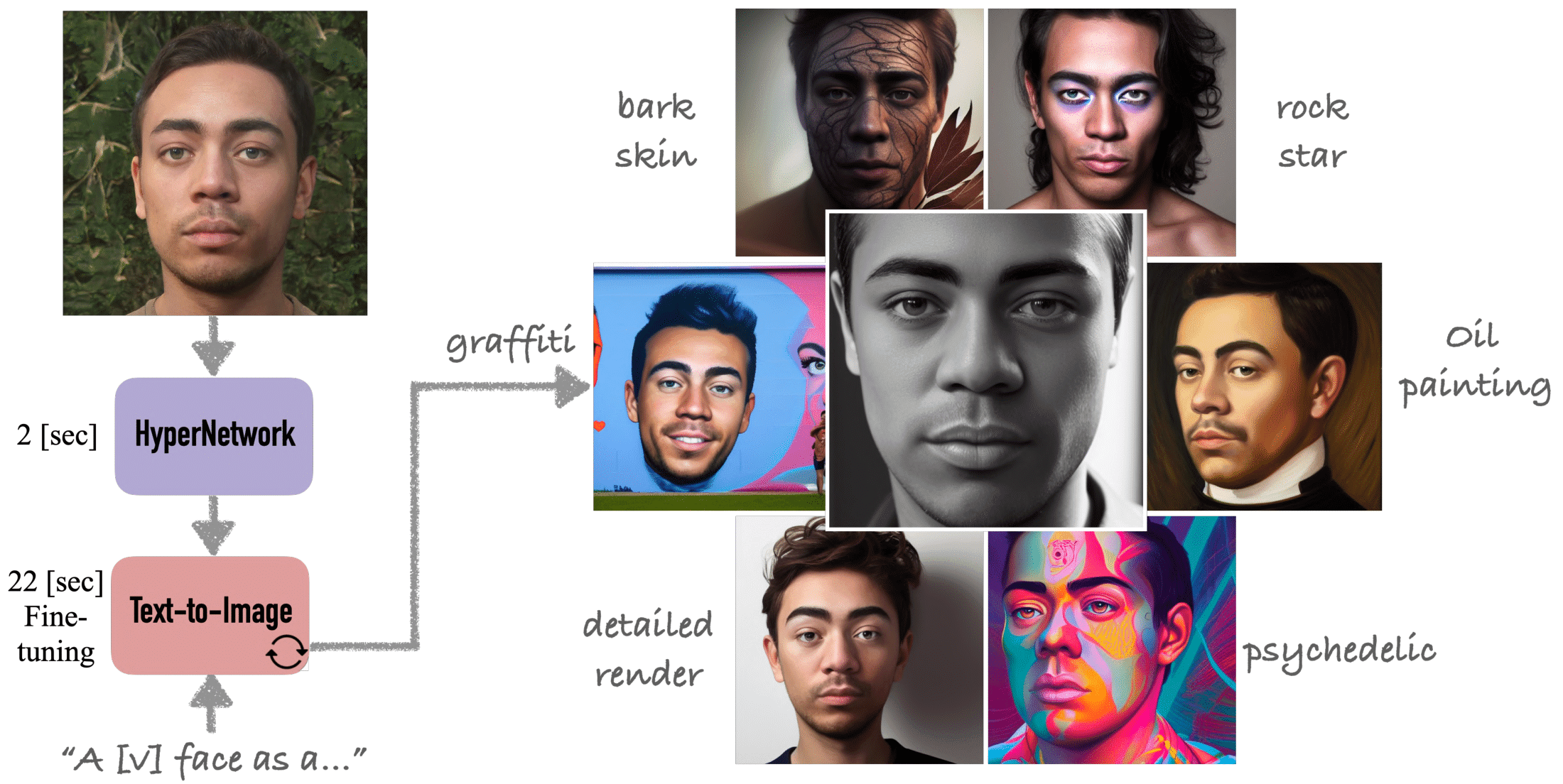
HyperDreamBooth is a new powerful method that can generate a person’s face in various contexts and styles from a single input image. It is much faster and smaller than the traditional methods of text-to-image personalization and can personalize models to a much higher degree of detail.
The method was proposed by a team from Google Research.
It can achieve personalization on faces in roughly 20 seconds, 25x faster than DreamBooth and 125x faster than Textual Inversion, using as few as one reference image, with the same quality and style diversity as DreamBooth. It also yields a model that is 10000x smaller than a normal DreamBooth.

Whether you want to create your own avatar, try on different outfits, edit your photos or make art that reflects your style, HyperDreamBooth can do it all.
HyperDreamBooth compared to DreamBooth
DreamBooth is a method that leverages diffusion models to create realistic images of various people in different scenarios and styles, while preserving their identities. However, this requires a lot of time and memory to customize the images for each person. DreamBooth takes around 5 minutes to train on one subject with 1K iterations.
HyperDreamBooth diffusion model solves the size and speed problems of DreamBooth by using 3 core elements:
- Lightweight DreamBooth (LiDB), a small personalized text-to-image model
- HyperNetwork, a network that generates LiDB weight from a single image
- Rank-relaxed fast fine-tuning, a technique that improves subject fidelity by relaxing the rank of LoRA DreamBooth model during optimization.
(1) Lightweight DreamBooth (LiDB)
LiDB is a text-to-image diffusion model that is based on the LoRa model. The diagram below illustrates the idea behind the model.

The Down (A) and Up (B) matrices of the LoRA model are decomposed into two matrices each (“Aux” and “Train”). The “Aux” layers are randomly initialized with row-wise orthogonal vectors and are frozen.
This allows LiDB to achieve a significant reduction in the number of parameters (only 30K trainable variables and 120 KB in size), while still maintaining the quality of the images generated.
(2) HyperNetwork
The HyperNetwork predicts the low-rank residuals (a subset of network weights from a face image). Its inputs are the latent features from the Visual Transformer (ViT) Encoder and its output is a set of weights that are used to initialize the diffusion model (see the picture below).

The HyperNetwork architecture in the HyperDreamBooth model has a few advantages over traditional methods of text-to-image personalization.
- It is much faster. This is because the HyperNetwork can be trained separately from the diffusion model, and the weights for the diffusion model can be generated quickly once the HyperNetwork is trained.
- It has a more flexible architecture.
- It is more efficient. The HyperNetwork only needs to be trained once, and the weights for the diffusion model can be generated quickly for any new input image.
The approach of using a HyperNetwork to predict the initial weights for a model, and then fine-tuning the model, achieves the best results (see the picture below).

(3) Training and fast fine-tuning
HyperDreamBooth is a two-phase process:
- HyperNetwork training on a dataset of images and text descriptions. The goal of the training is to teach the HyperNetwork to predict network weights that will cause the diffusion model to generate images that match the text descriptions.
- Fast fine-tuning used to adjust the personalized weights that were generated by the HyperNetwork to improve the quality of the generated images.

The combination of the HyperNetwork and fast fine-tuning allows HyperDreamBooth to customize a text-to-image diffusion model with just one input image with high accuracy while preserving the style of the model.
Comparisons
1. Qualitative comparison. The figure below shows a qualitative comparison of random generated samples using HyperDreamBooth, DreamBooth and Textual Inversion, for two different identities and five different stylistic prompts.

HyperDreambooth generally outperforms the competing methods. It maintain the model’s style and the subject’s identity with high accuracy
2. Quantitative comparison. HyperDreambooth was evaluated on face identity preservation (Face Rec.), subject fidelity (DINO, CLIP-I) and prompt fidelity (CLIP-T) against DreamBooth and Textual Inversion. The table below proves that the new method outperforms DreamBooth and Textual Inversion.
| Method | Face Rec. ↑ | DINO ↑ | CLIP-I ↑ | CLIP-T ↑ |
|---|---|---|---|---|
| HyperDreamBooth | 0.655 | 0.473 | 0.577 | 0.286 |
| DreamBooth | 0.618 | 0.441 | 0.546 | 0.282 |
| Textual Inversion | 0.623 | 0.289 | 0.472 | 0.277 |
3. The research team carried out a user study for face identity preservation of outputs and compared the HyperDreamBooth method to DreamBooth and Textual Inversion. The table below shows a strong preference for face identity preservation of the HyperDreambooth method.
| Method | Identity Fidelity ↑ |
|---|---|
| HyperDreamBooth DreamBooth Undecided | 0.648 0.233 0.119 |
| HyperDreamBooth Textual Inversion Undecided | 0.706 0.216 0.078 |
Societal Impact
HyperDreamBooth is a method that allows people to explore different aspects of their identity, boosting their creativity and ability to express themselves through creations in a simple manner.
However, this can also have some negative implications, such as creating false or malicious images, violating other people’s rights, generating biased or offensive images, or affecting people’s self-esteem. Future research in this field should address these challenges.
Conclusion
HyperDreamBooth is a promising new technique to quickly personalize text-to-image models.
The method utilizes a HyperNetwork to generate personalized weights and further improves them through fast fine-tuning.
With just one reference image of a person, the method can generate diverse and realistic images of the person’s face in different styles and contexts.
HyperDreamBooth outperforms existing methods in terms of speed and size, while maintaining a high level of accuracy and model integrity.
Learn more:
- Research paper: “HyperDreamBooth: HyperNetworks for Fast Personalization of Text-to-Image Models” (on arXiv)
- Project page






