MiniGPT-4 is a recently released foundational language model that can recognize visual features in images and produce corresponding descriptions, exhibiting comparable capabilities to GPT-4.
Created by a team from King Abdullah University of Science and Technology, the open source MiniGPT-4 has been receiving a lot of attention in the research community.
MiniGPT-4 exhibits remarkable abilities, including the generation of detailed descriptions of images, the detection of interesting or peculiar features in images, and the creation of websites from handwritten instructions.
Furthermore, MiniGPT-4 can identify and solve problems within images, generate poetry or rap based on images, write stories based on images, create ads for products it identifies in images, and instruct users on how to cook certain dishes using images as a guide.
The model
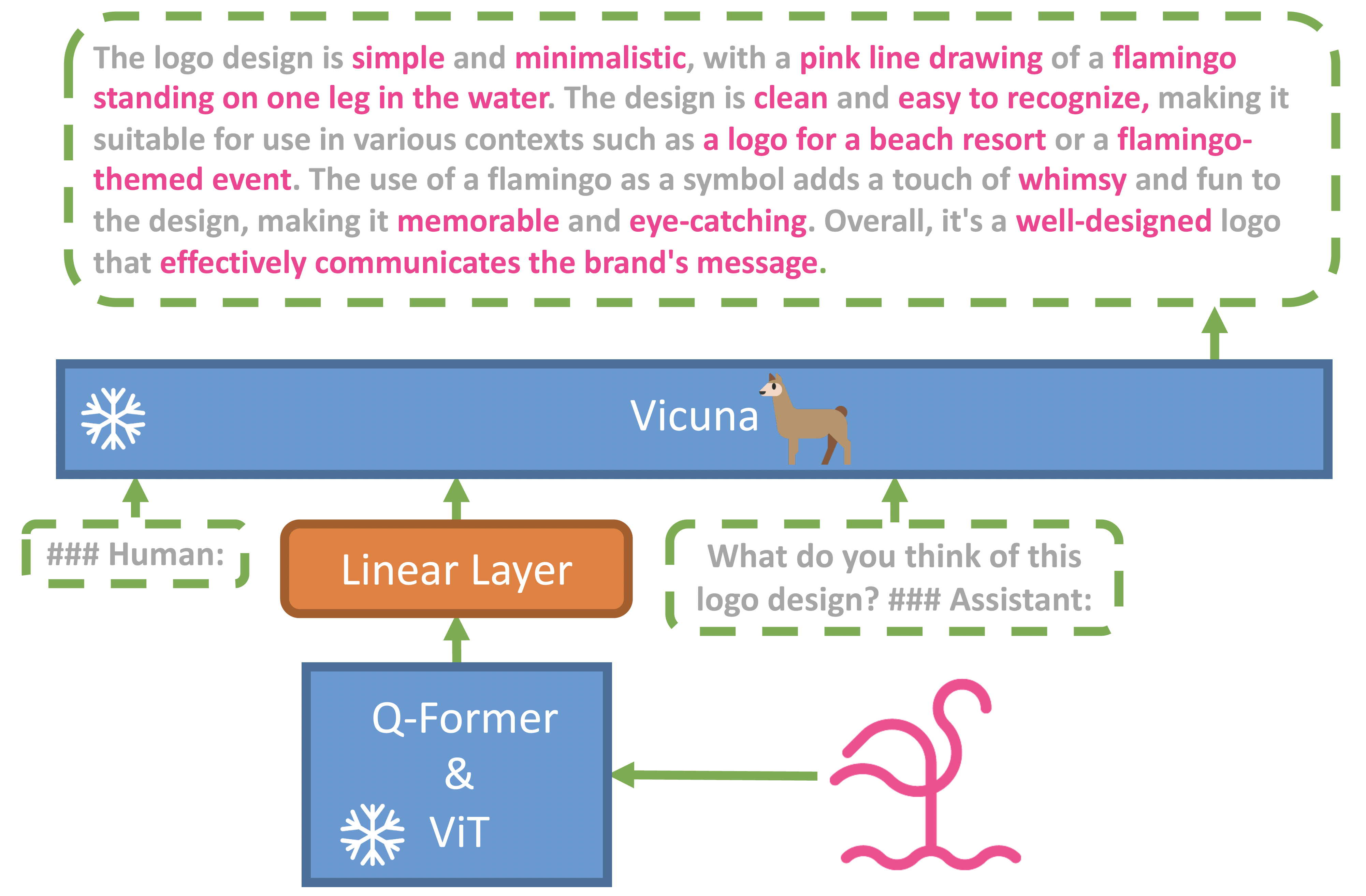
MiniGPT-4 architecture (see picture below) comprises a pretrained ViT and Q-Former vision encoder, a single linear projection layer, and an advanced Vicuna large language model. The linear projection layer is the only component that needs to be trained to align the visual features with the Vicuna, making MiniGPT-4 an efficient model.
Vicuna and vision models are open-source.

Training details
MiniGPT-4 was trained through a two-stage process: (1) a pretraining stage on a large, general dataset and (2) a fine-tuning stage using a smaller, high-quality dataset.
(1) Pretraining stage: the pretrained vision encoder and Vicuna were kept frozen, and only the linear projection layer was trained on a large dataset containing millions of image-text pairs.
The purpose of the linear projection layer was to create a bridge between the pretrained vision encoder and Vicuna. It takes the encoder’s output and converts it into a text token or prompt that is further used by Vicuna to produce corresponding ground-truth texts.
This pipeline allowed the model to understand the visual characteristics of various objects, people, and locations, and subsequently learn how to describe them in words.
During this stage the authors noticed some issues with MiniGPT-4’s output including the generation of repetitive, fragmented sentences with irrelevant content. To address these problems, they performed the fine-tuning stage.
(2) Fine-tuning stage: the pretrained model was fine-tuned with a smaller but high-quality image-text pairs to further improve it. They utilized a conversational template containing different variants of instructions such as “Describe this image in detail” or “Can you tell me about the contents of this image?”
- The training process used approximately 5 million image-text pairs and took roughly 10 hours and employed four A100 (80GB) GPUs.
- The fine-tuning process used a combination of 3,500 image-text pairs and it was completed within 7 minutes using a single A100 GPU.
Test results
MiniGPT-4 has demonstrated a range of impressive capabilities similar to those of GPT-4, including generating detailed image descriptions, identifying amusing or unusual aspects within images, and even creating websites from handwritten text.
It can identify and provide solutions to problems within images, compose poetry or rap inspired by images, write stories based on images, create advertisements for products that it identifies in images, and even teach users how to cook certain dishes using images as a guide.


These diverse examples highlight the robustness and versatility of our MiniGPT-4.
Conclusion, further research
MiniGPT-4 offers three main advantages: it is totally free, highly computationally efficient, and demonstrates similar capabilities to GPT-4.
It represents a significant step forward in natural language processing and image recognition, having potential applications across various domains including advertising, e-commerce, and education.
The authors suggest that fine-tuning and human feedback may be necessary for MiniGPT-4 to improve its language outputs and become more natural, similar to how GPT-3 evolved into GPT-3.5.
Learn more:
- GitHub repository (paper, code, demo, video, dataset, and model)
- Related paper: “BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models” (on arXiv)






