
LucidDreamer is a generative tool that can create highly realistic 3D scenes from various input types, such as text descriptions, RGB, and RGBD, with no domain restriction. It leverages the power of Stable Diffusion, depth estimation, and 3D Gaussian splatting.
It generates multi-view images from Stable Diffusion and uses two iterative steps (Dreaming and Alignment) to generate and refine 3D Gaussian splatting scenes.
The model is open source and was developed by a research team from the Seoul National University. You can check out the website and code of LucidDreamer here.
3D scene generation challenges
3D scenes are digital representations of a physical environment that can be viewed from any angle and perspective. 3D scenes require more information and processing than videos, as they need to capture the shape, color, texture, and lighting of the objects in the scene. They provide more realistic and immersive experiences than videos.
Traditionally, 3D scene generation models have been constrained to specific domains due to their reliance on training data from that domain. For instance, a model trained on indoor scenes would struggle to generate realistic outdoor environments. This limitation has hindered the widespread adoption of 3D scene generation techniques.
LucidDreamer addresses these problems by using a diffusion-based generative model that can inpaint images from any domain. It does not rely on any 3D scan dataset or domain-specific prior knowledge and can generate 3D scenes with various styles and views.
Pipeline
The pipeline of LucidDreamer consists of 2 main steps:
- Point Cloud Construction: the input image (optionally, text-to-image by Stable Diffusion) is used to create an initial cloud of 3D points that is further enlarged to make a big scene, using iterative navigation and dreaming. Then the generated images are aggregated into a 3D scene using a novel aligning algorithm (alignment).
- Gaussian splats optimization: the extended point cloud is converted to 3D Gaussian splats to enhance the quality of the 3D scene.
More details can be seen in the picture below.
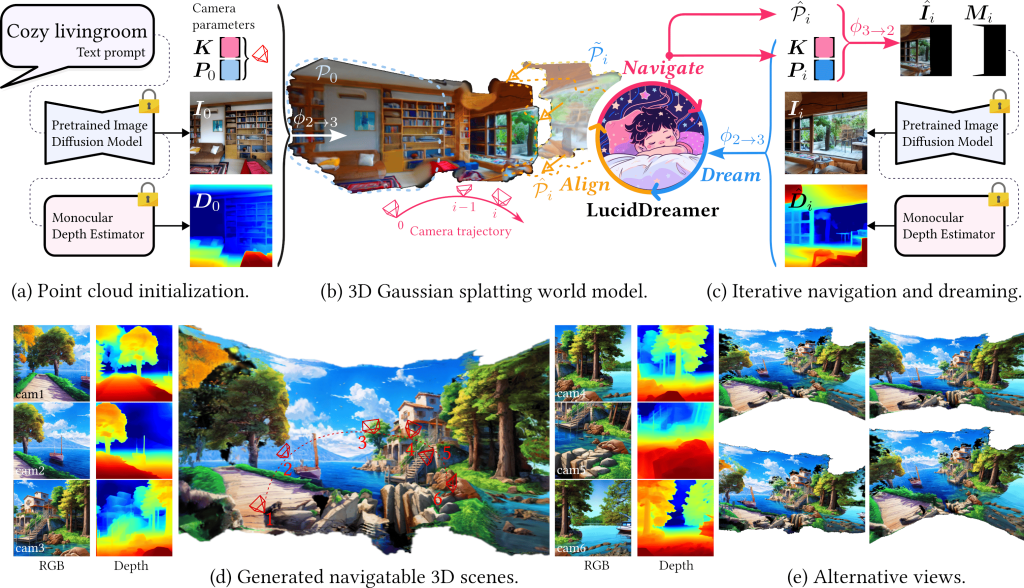
I. Point Cloud Construction
The point cloud construction starts with creating an initial point cloud (𝒫0) by converting the input RGBD image (RGB + depth map) to 3D space. The model inputs are: the depth map (D0), the generated image (I0), the intrinsic and extrinsic matrices (K and P0) that define the camera properties. If a text prompt is provided, LucidDreamer uses a pretrained image diffusion model to generate a relevant RGB image.
Then the model maintains and expands the point cloud by sequentially attaching new points through a 3-stage iterative process:
- Navigation: select a desired view for image generation, based on the point cloud and the text prompt. The camera is moved and rotated from the previous position (Pi−1) to Pi.
- Dreaming: generate an image from the current camera position Pi, using a pretrained diffusion model. The change in camera position and pose may cause some areas in the new image to be missing or occluded, and they need to be inpainted with the help of the depth map estimation. The inpainted images are then are lifted into 3D space (converted from 2D to 3D point clouds) using camera tracking.
- Alignment: integrate the newly generated 3D points into the existing scene using an alignment algorithm.
II. Gaussian splats optimization
After the point cloud is generated, LucidDreamer uses a 3D Gaussian splatting model to render the scene. This is a way of representing and rendering a 3D scene using small blobs of color and opacity, called 3D Gaussians. Each 3D Gaussian has a position, orientation, scale, color, and opacity that describe how it looks from different viewpoints.
Experimental results
The following datasets were used:
- for the text inputs, they randomly generated text prompts related to the scene images and used Stable Diffusion to produce the initial image.
- for the RGB images, they used real or generated high-quality images.
- for the RGBD inputs, they used the ScanNet and NYUdepth (which provide ground truth depth maps) and Stable Diffusion to inpaint the masked regions of the image.
- LucidDreamer does not require a training dataset.
LucidDreamer outperforms other methods and is capable to generate realistic 3D scenes from various input domains and formats, maintaining their input style.
In the picture below the authors illustrate how the point cloud evolves and the final 3D model varies for different text inputs, starting from the same initial image (I0).

Conclusion
LucidDreamer is a powerful and versatile 3D scene generation method, without being constrained to specific domains. The model supports multiple input formats (text or RGB) and styles (e.g. lego, anime). Unlike other models that imitate the style of the training dataset, LucidDreamer preserves the style of the input image along the scene.
You can control the 3D scene and can generate different views of the scene by changing the camera path.
You can try out LucidDreamer online on Huggingface, in this Collab, or use the gradio demo locally. For more details, see the Install and Usage sections in the project repository.
Learn more:
- Research paper: “LucidDreamer: Domain-free Generation of 3D Gaussian Splatting Scenes” (on arXiv)
- Project page






