
MinerU2.5 (paper, code) is a parsing vision-language model that converts complex documents, such as PDFs, into machine-readable formats, such as markdown or JSON. These outputs can be easily processed by software systems, making the tool valuable for search engines, analytics platforms, and machine learning pipelines.
Developed by a research team from Shanghai AI Lab, Peking University and Shanghai Jiao Tong University, MinerU2.5 is a 1.2B-parameter vision-language model (VLM) that outperforms big models like GPT-4o and Gemini-2.5 Pro, while using far less computing power.
Applications
MinerU2.5 provides the clean data required by AI-driven content analysis and decision support. Some example use cases:
- Training and fine-tuning LLMs. MinerU2.5 delivers high-quality, de-duplicated, and properly ordered text for training and fine-tuning LLMs.
- Improving Retrieval-Augmented Generation (RAG) systems. High-quality structure leads to high-quality retrieval. By accurately parsing context, MinerU2.5 ensures the LLM’s answers are precise and grounded in the document.
- Academic and research workflows. It turns scientific papers into clean computer formats (LaTeX for math and code, JSON for organized data), thereby supporting literature review automation and citation extraction.
- Deep content and business process automation. It extracts specific, labeled entities (e.g., invoice numbers or contract clauses) and organizes them into structured data formats (such as JSON or database entries), which can then be used by advanced financial and analytical tools.
How to use it
Online demos are available on HuggingFace and ModelScope. There’s also an official demo (it requires login, in Chinese by default).
You can also use it locally and integrate it into your document processing workflows. Follow the Local Deployment section in the GitHub repository. You can install it either from source code or using Docker. The code is released under the AGPL open-source license.
MinerU2.5 uses a two-stage parsing strategy
Documents such as PDFs and scanned reports include large images, dense text, and complex page layouts. Analyzing them at full resolution keeps small details, but requires a lot of computing power. Reducing the resolution makes processing faster but may remove important information, such as the structure of paragraphs, tables, and equations on the page.
The two most common document parsing methods have shortcomings. Pipeline-based approaches are modular and easier to interpret but prone to error propagation. In contrast, end-to-end Vision-Language Models (VLMs) offer better semantic understanding but struggle with efficiency, hallucination in long documents, and token redundancy.
MinerU2.5 addresses these limitations with a two-stage architecture that separates global layout analysis from local content recognition. First, it downsamples images to quickly identify the structural elements and then, it zooms into native-resolution crops to extract the local information with high fidelity. This “coarse-to-fine” design reduces overhead and preserves detail, especially in dense or technical documents.
Key advantages
- Reduced computational load. MinerU2.5’s decoupled architecture minimizes the need for end-to-end processing of high-resolution documents. Instead of feeding the entire pages into a single model, it first performs lightweight layout analysis at a lower resolution and then selectively applies high-resolution recognition only to relevant regions. This targeted approach significantly reduces memory usage and GPU demands, making the model more accessible for deployment on standard hardware.
- Faster processing. The model can quickly identify structural elements like headers, tables, and figures, and then process them in parallel or asynchronously. This modularity leads to faster inference times, especially when handling multi-page or densely formatted documents.
- Accuracy. It achieves high accuracy in layout detection and content extraction, consistently outperforming previous models in preserving document structure. Because it recognizes content at the original resolution, it can handle fine text, math equations, and small fonts better than models that rely on uniform downsampling.
The model
MinerU2.5’s architecture is inspired by the Qwen2-VL framework and follows a two-stage “coarse-to-fine” pipeline, as illustrated in the figure below.
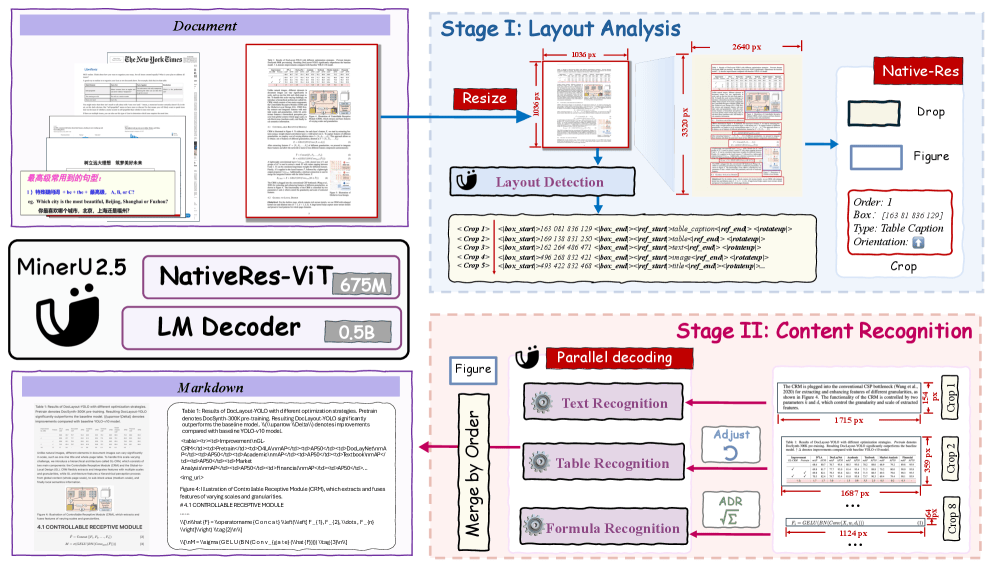
- Stage 1: Layout analysis on downsampled images. The input document is first downsampled (lower resolution), yielding a global, coarse version of the page. A layout analysis module processes this image to detect structural elements: text blocks, tables, formula regions, figures, etc. Lower resolution means lower computation.
- Stage 2: Content recognition on cropped high-resolution patches. Based on the layout from Stage 1, the model extracts native-resolution crops from the original document image. Each crop is fed into a content recognition module, which reads text, formulas, tables, etc., preserving detail. Because only relevant crops are processed, the system avoids processing the full high-res image unnecessarily.
Training
MinerU2.5 was trained in three main phases. The first phase, called modality alignment, focused on ensuring that the vision encoder (NaViT) and the language decoder (Qwen2-Instruct) could work together smoothly. After this, the model went through large-scale pretraining to learn general document parsing skills, followed by fine-tuning to handle difficult cases such as complex tables or multilingual text.
To make this multi-stage process possible, the researchers built a powerful data engine that generates diverse, large-scale training datasets, providing the model with the variety it needs to perform well in real-world scenarios.
Evaluation
To measure how well MinerU2.5 performs in real-world scenarios, the researchers carried out a detailed quantitative evaluation across several document parsing tasks, such as layout detection, text recognition, table parsing, formula understanding. They compared MinerU2.5 with some of today’s most powerful general-purpose VLMs, including GPT-4o, Gemini 2.5 Pro, and Qwen2.5-VL, as well as domain-specific VLMs, such as dots.ocr, MonkeyOCR, and olmOCR.
The evaluation was split into two parts:
- Full-document parsing task. The model was tested on three benchmarks: OmniDocBench, Ocean-OCR, and olmOCR-bench for robustness and generalization capabilities.
- Element-specific parsing task. This section tested detailed skills like layout analysis, table understanding, and formula recognition.
This two-part approach gives a complete picture of MinerU2.5’s strengths, from broad document comprehension down to the smallest details in equations and data grids.
MinerU2.5 outperformed both massive multimodal models and specialized document parsers, all while using significantly less computational power (see the picture below).
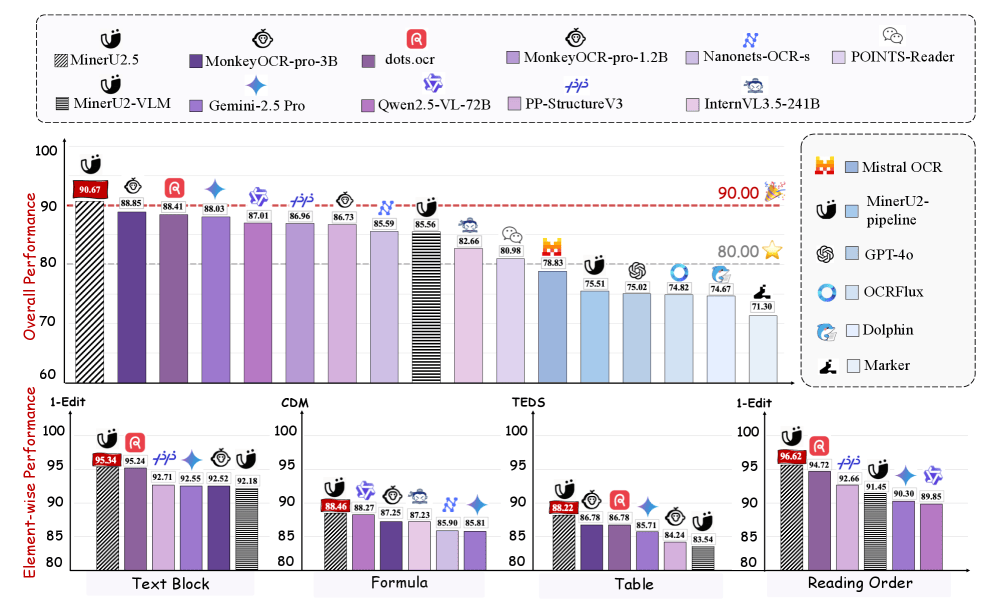
When tested on full-page parsing, it not only extracted textual content precisely but also preserved complex visual structures like tables and formula layouts with impressive fidelity.
Remarkably, it achieved this level of performance while using 40–60% less computational power than larger multimodal models like GPT-4o and Gemini 2.5 Pro. This efficiency advantage comes from its “coarse-to-fine”, two-stage design, which performs global layout analysis on low-resolution images before selectively refining high-resolution regions that contain dense or critical information.
As a result, MinerU2.5 delivers faster inference, reduced operational costs, and strong scalability across extensive document collections, without compromising recognition accuracy.
Conclusion
MinerU2.5 is a highly efficient, 1.2B-parameter VLM that transforms unstructured documents into machine-readable data, precisely extracting elements such as tables, formulas, and reading order. It accurately extracts complex elements such as tables, formulas, and reading order, ensuring that retrieval-augmented generation (RAG) systems can consistently access the right information.
Overall, it provides the foundational, high-quality data needed to power modern document AI applications.
Read more:
- Paper on arXiv: “MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing”
- HuggingFace (model, demo)
- ModelScope (model, demo)
- GitHub repository





