SparseGPT is a new approach for pruning massive GPT models. It was proposed by Elias Frantar and Dan Alistarh from ISTA (Institute of Science and Technology) Austria and Neural Magic.
SparseGPT can reduce the size of large GPT-family models by at least 50% in one shot, without any retraining and with minimal loss of accuracy.
The SparseGPT approach
The method was tested on the largest available models and was able to achieve 60% sparsity with no significant increase in perplexity. It works by removing unimportant weights from the model after each pruning step, while preserving the input-output relationship for each layer.
The weight updates are computed without using any global gradient information, allowing the method to directly identify sparse, accurate models in the vicinity of the dense pretrained model.
In this way, more than 100 billion weights from the models can be ignored during inference, with no accuracy loss.
The model
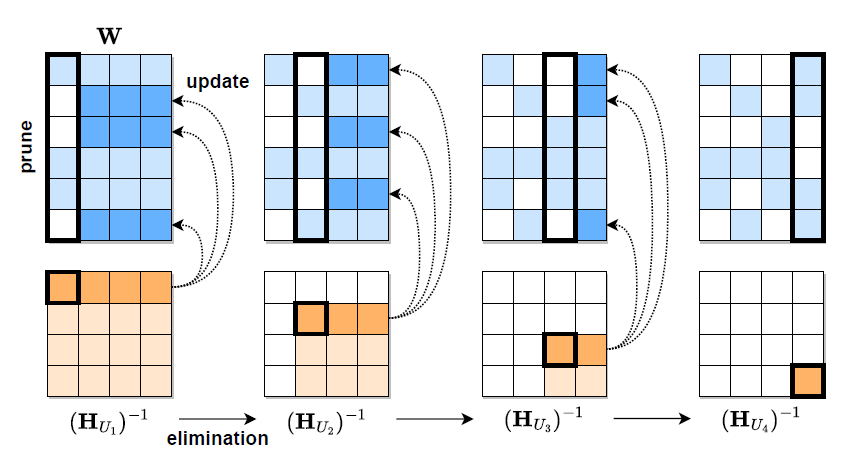
SparseGPT was implemented in PyTorch and the research team used the HuggingFace Transformers library for handling models and datasets. The basic algorithm is visualized in the picture below.

Given a fixed pruning mask M, the weights are incrementally pruned in each column of the weight matrix W, using a sequence of Hessian inverses (HUj)−1, and updating the remainder of the weights in those rows, located to the “right” of the column being processed.
Respectively, the weights to the “right” of a pruned weight (dark blue) will be updated to compensate for the pruning error, whereas the unpruned weights do not generate updates (light blue).
Conclusion, future research
The authors found that large-scale generative pretrained Transformer family models are easy to sparsify via weight pruning.
Their proposed method, SparseGPT shows that the largest open-source GPT-family models (e.g. OPT-175B and BLOOM-176B) can be reduced to reach more than 50% sparsity without affecting their accuracy.
The team encourages future work on compressing massive models through fine-tuning mechanisms and considers that progressive pruning and fine-tuning techniques can lead to 80-90% sparsity.
They also plan to investigate how to reduce the computational cost of pre-training these large-scale, massive models.






