The University of California, Santa Cruz research team has introduced an energy-efficient approach called SpikeGPT to train large language models (LLMs).
LLMs, such as GPT, are commonly pre-trained on massive amounts of text data, requiring significant computing resources and energy. For instance, the training of GPT-3 was projected to consume 190,000 kWh of energy.
The proposed SpikeGPT model exhibits comparable performance to its predecessors, while consuming less energy. It achieves this by combining the generative pre-trained language (GPT) model with spiking neural networks (SNN).
SpikeGPT
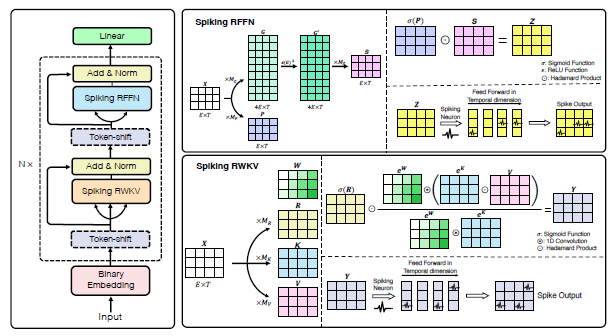
The picture below illustrates the architecture of the model.

Legend
Binary Embedding convert the continuous outputs of the embedding layer into binary spikes
Token Shift predict the next word in a sequence
SRWKV (Spiking Relative Position Weighted Key Value) capture the relative position of tokens within the input sequence
SRFFN (Spiking Receptance Feed-Forward Networks) a gating mechanism applied to normalized and token-shifted output of each SRWKV module
Spiking neural networks
Spiking neural networks (SNNs) are a subtype of artificial neural network (ANN) model that are designed to consume less energy. They are based on the way that neurons in the brain communicate with each other using brief electrical signals, known as spikes.
Unlike traditional ANNs that utilize continuous-valued signals to activate neurons, SNNs use these discrete spikes to transmit information between neurons. This feature enables SNNs to more accurately replicate the behavior of biological neurons, resulting in a higher level of energy efficiency compared to ANNs.
SNNs face significant challenges with regard to their training complexity and dependence on specialized hardware to operate effectively. However, to overcome these obstacles, the research team suggests a novel method that involves language-generation using direct-SNN training.
Research methodology and test results
The binary embedding block converts input tokens into binary values which are then streamed in a sequential manner to the attention mechanism, similar to conventional spiking neural networks.
To address the challenge of quadratic computational complexity, the multi-head self-attention mechanism of the transformer block was replaced with a linear attention mechanism that is capable of handling longer sequences.
SpikeGPT was trained on three variants with 45M, 125M, and 260M parameters, and the results of the testing demonstrated that SpikeGPT can perform comparably to non-spiking ANN models on the tested benchmarks, while consuming significantly less energy – up to 5 times less.
Conclusion
The paper demonstrates the potential of using spiking neural networks for natural language processing and shows that SpikeGPT can achieve similar performance to traditional GPTs, with lower computational costs.
The authors claim that SpikeGPT is the largest functional backpropagation-trained SNN model to date, with 4x more parameters than any previous model.
While this field is still in its early stages, it holds promise for creating more intelligent and human-like AI systems.
Learn more:
- Research paper: “SpikeGPT: Generative Pre-trained Language Model with Spiking Neural Networks” (on arXiv)
- GitHub repository






