
Imagine a home robot that learns to tidy up simply by watching online videos, or an industrial robot that mimics human behavior by analyzing footage from the workplace. No labels. No instructions. Just observation. That’s exactly what V-JEPA 2 (paper, blog, code) is trying to achieve.
Developed by Meta’s FAIR team, V-JEPA 2 (Video Joint Embedding Predictive Architecture 2) is the first world model trained entirely on video, that allows understanding and predicting events at a state-of-the-art level, along with the ability to plan and control robots in unfamiliar settings.
By training on large collections of video, the model learns to capture object motion, recognize cause-and-effect patterns, and anticipate future events, much like humans intuitively learn by observing the world around them.
The robotic variant, V-JEPA 2-AC, can perform planning and robot control such as reaching, grasping, and pick-and-place in new environments.
The team has also released three new benchmarks to help the research community compare different AI models fairly and track progress in video-based learning and reasoning.
What V-JEPA 2 can do
- Understand: It learns the structure of the world: what things are, how they move, how they interact.
- Predict: It can guess what will happen next in a video, even when something is hidden or missing.
- Plan: Given a goal, like reaching for an object, it can plan a sequence of actions that make it happen.
The model
V-JEPA 2 is a large AI model with 1.2B parameters, built on Meta’s Joint Embedding Predictive Architecture (JEPA), first introduced in 2022. Last year Meta released V-JEPA, their first video-based model. V-JEPA 2 extends V-JEPA with improved action prediction and more advanced world modeling capabilities, enabling robots to adapt to new environments and carry out tasks with minimal additional training.
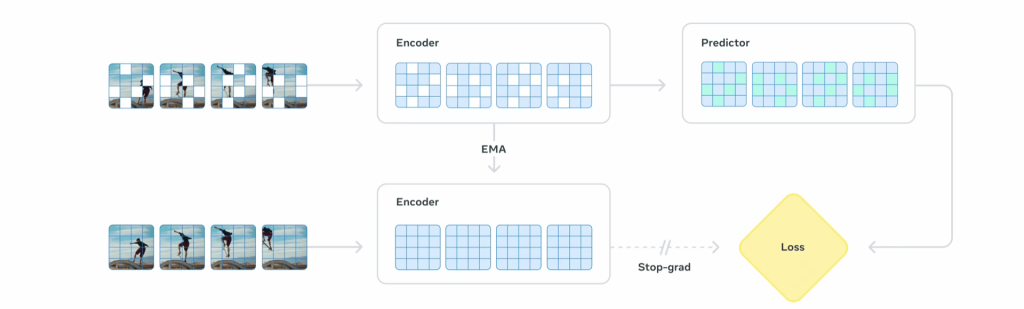
V-JEPA 2 includes two core components (see the picture below):
- An encoder: Processes raw video and converts it into embeddings, which are numerical representations that capture important information about the current state of the world.
- A predictor: Takes these embeddings, along with information about what needs to be predicted, and generates predicted embeddings representing the expected future state or outcome.
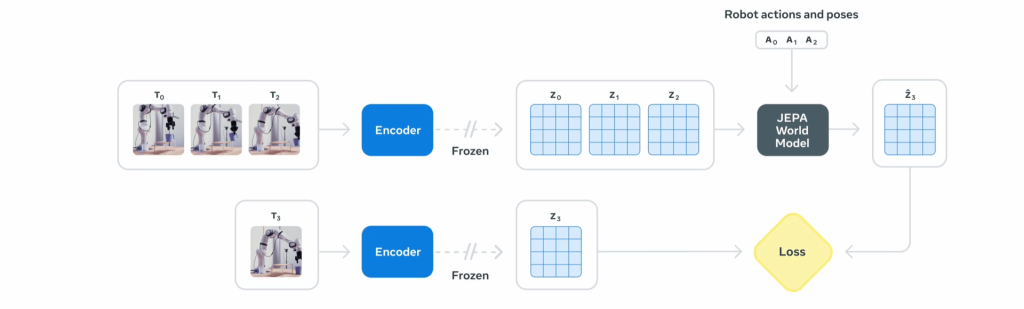
Action-conditioned head (V-JEPA 2-AC) builds on V-JEPA 2’s visual understanding by incorporating robot interaction data, allowing robots to plan and execute manipulation tasks with minimal additional training.
The figure below shows the pre-trained model, V-JEPA 2, alongside its robotic extension, V-JEPA 2-AC, and their respective applications.
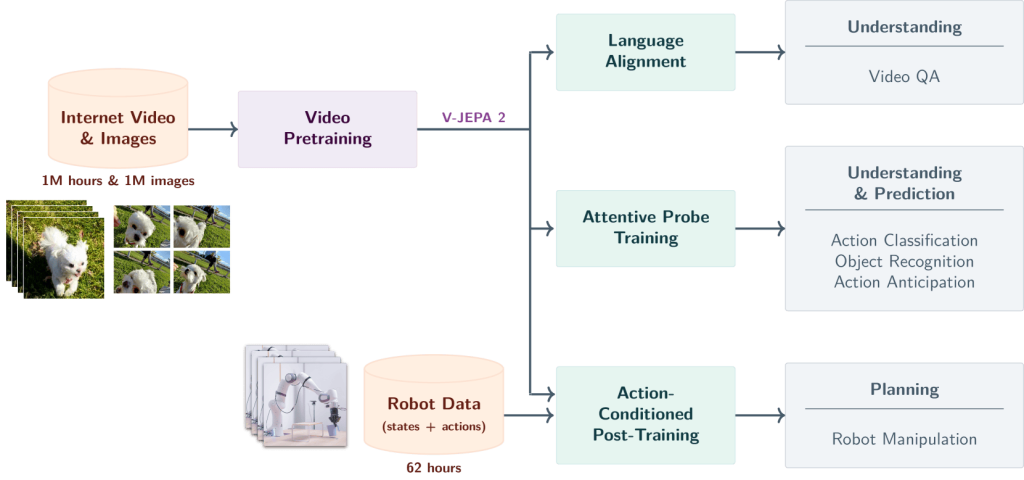
- V-JEPA 2 (pre-trained model): Can be applied to a variety of video understanding tasks, such as action classification, object recognition, action anticipation, and video question answering, by aligning its embeddings with an LLM backbone.
- V-JEPA 2-AC (extended robotic model): Designed for robot manipulation tasks, it plans and executes actions within a model predictive control (MPC) framework, enabling robots to interact with new environments effectively.
Multistage training
V-JEPA 2 is trained through self-supervised learning on video data, removing the need for manual annotations. The training is carried out in two stages
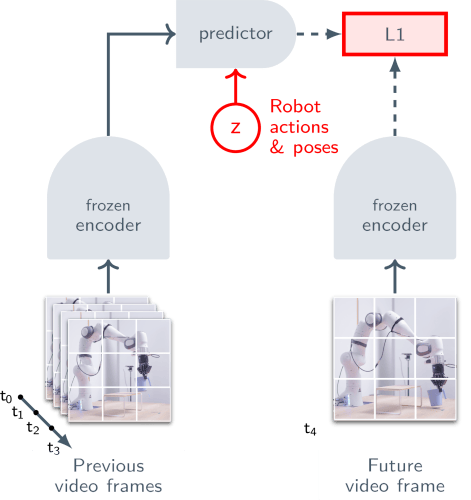
I. Actionless pre-training with large-scale visual data: V-JEPA 2’s encoder and predictor are pretrained with up to 1B parameters on a dataset of 1M hours of video and 1M images from the internet. The picture below shows how the model uses a visual mask denoising prediction technique, where parts of the video frames are hidden (masked) and the model learns to predict these missing parts in a learned representation space. Unlike traditional methods that generate videos frame by frame, which is computationally expensive and often captures irrelevant visual details, V-JEPA 2 focuses on learning the most important, predictable aspects of a scene, such as how objects move and interact.
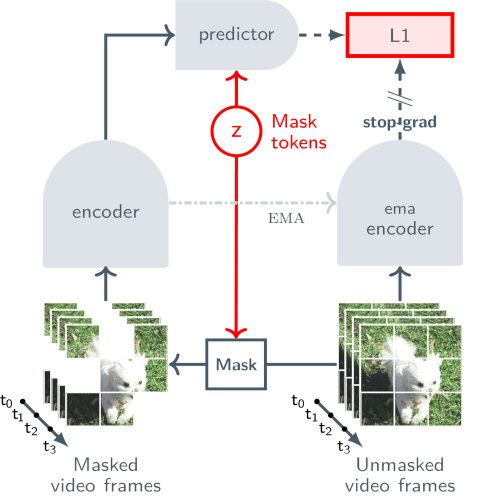
This training stage enables the model to understand how humans manipulate objects, how objects move in the physical environment, and how they interact with one another. When aligned with a language model, the model reaches state-of-the-art results on video QA benchmarks like Perception Test and TempCompass.
II. Action-conditioned training (see the figure below): After pretraining, V-JEPA 2 is adapted for robotics. The video encoder is frozen, and a new 300M-parameter transformer is trained on 62 hours of robot trajectory data from the DROID dataset. This action-conditioned model, V-JEPA 2-AC, predicts future video embeddings based on past states and executed actions, allowing robots to plan and carry out manipulation tasks effectively.
Zero-shot robot planning
V-JEPA 2 supports zero-shot deployment in new environments with unseen objects. Unlike other models requiring environment-specific data, it is trained on the open-source DROID dataset and deployed directly on lab robots. It successfully performs tasks such as reaching, picking, and placing.
For short-horizon tasks, such as picking or placing an object, a goal image is provided. The encoder generates embeddings for current and goal states, and the predictor evaluates candidate actions to select the most effective one via model-predictive control.
For longer-horizon tasks, for example, grasping an object and placing it in the correct location, a sequence of visual subgoals guides the robot, mimicking human-like learning. This approach achieves 65–80% success rates in pick-and-place tasks with novel objects and settings.
V-JEPA 2 benchmark results
The following table presents V-JEPA 2’s performance across multiple benchmarks, compared with the previous best models in three key areas: robot control, prediction, and visual understanding.
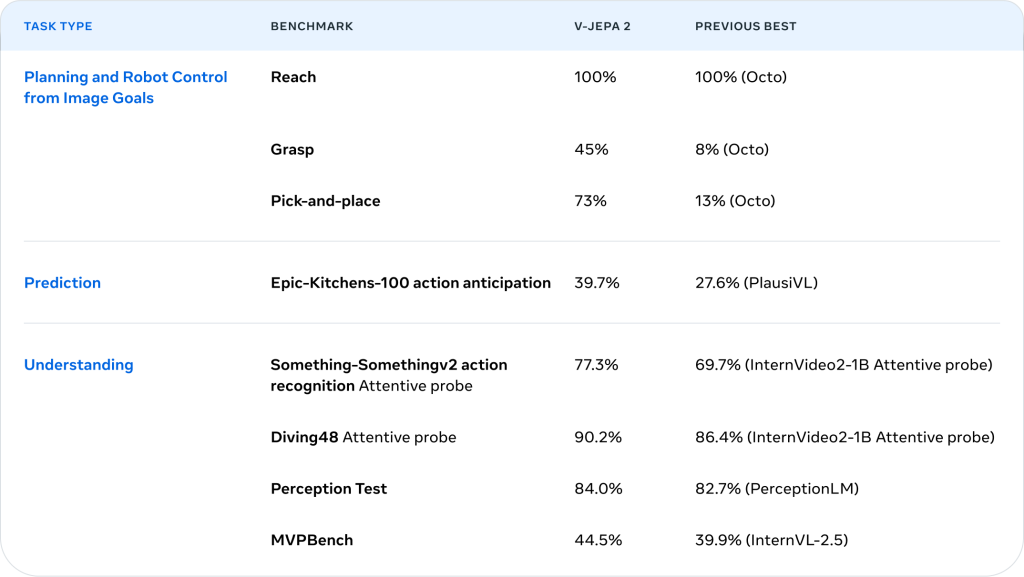
Task results:
- Planning and robot control from image goals: V-JEPA 2 matches Octo in reaching goals and performs much better in grasping (45% vs. 8%) and pick-and-place tasks (73% vs. 13%).
- Prediction: In predicting what action will happen next in complex kitchen scenes, V-JEPA 2 performs significantly better than the previous best.
- Understanding: V-JEPA 2 achieves state-of-the-art performance across all of them, meaning it can better recognize and reason about complex visual input.
How to use V-JEPA 2
V-JEPA 2 is open source for non-commercial use under a Creative Commons license. Meta has released the code, pretrained model checkpoints, and benchmark datasets publicly. For commercial use, a separate license or permission from Meta is required.
To get started, follow a typical workflow for large AI models: set up your environment, load pretrained weights, and use the model for inference or fine-tuning on your tasks.
For full instructions, examples, and resources, visit the official V-JEPA 2 GitHub repository.
Potential applications
V-JEPA 2 has a wide range of potential applications, thanks to its strong capabilities in video understanding, future prediction, and action-conditioned planning.
In robotics, it can be used for autonomous manipulation tasks such as grasping, sorting, and assembling objects based on visual goals. Its ability to generalize across tasks without needing specific training makes it ideal for home assistance, enabling robots to help with everyday activities like fetching or cleaning. In industrial settings, it can perform complex operations in dynamic environments without requiring task-specific demonstrations.
In human-robot interaction scenarios, it allows machines to anticipate human movement, enabling smoother and safer collaboration.
In gaming and virtual environments, V-JEPA 2 can predict players’ actions and adjust responses accordingly. It can also learn game strategies by analyzing video footage.
Conclusion
V-JEPA 2 brings us closer to generalist AI agents, which are smart systems that can observe, understand, and act across many tasks and environments using videos. This approach aims to move AI closer to human-like adaptability, potentially enabling systems to take on entirely new tasks without prior experience.





