
YOLOv9 is a new version of YOLO (You Only Look Once), a powerful algorithm for object detection. It builds upon YOLOv7 by introducing two innovative techniques: Programmable Gradient Information (PGI) and the Generalized Efficient Layer Aggregation Network (GELAN).
These advancements allow YOLOv9 to not only detect objects more accurately but also do it faster compared to previous models. The model is open-source, see the code repository for installation, training and many useful links. You can try it online by uploading an image to this space on Huggingface.
The number of layers affects the information preservation. As the layers increase, all architectures tend to lose a greater amount of original information. The figure below shows that GELAN keeps more stable and clear edges than other architectures:
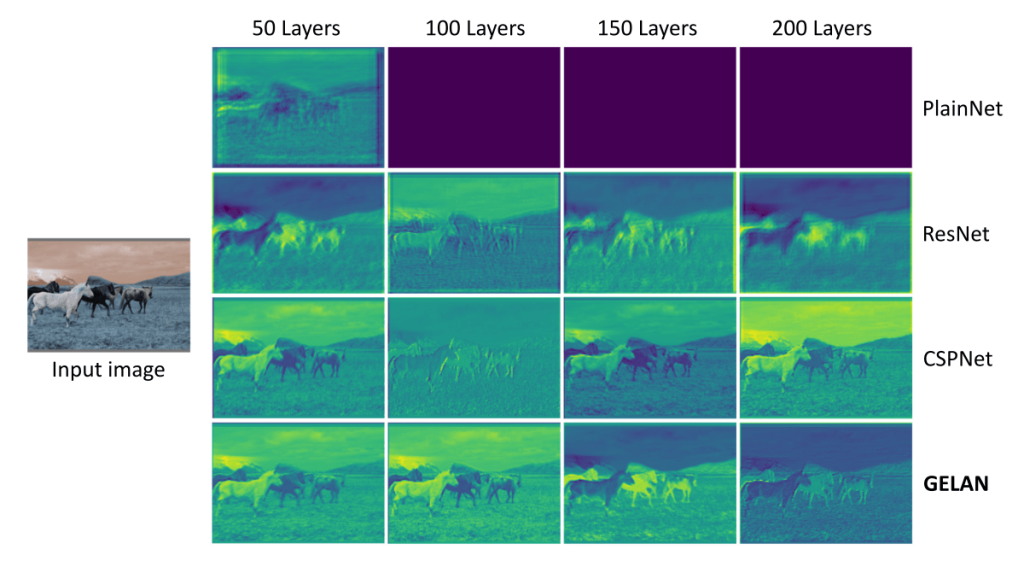
YOLOv9 represents an advancement in the YOLO family of object detection models, showing better performance than its predecessors (see the next table).
| Model | #ParamS (M) | FLOPs (G) | APval 50:95 (%) |
|---|---|---|---|
| YOLOv7-X | 71.3 | 189.9 | 52.9 (+1.1%) |
| YOLOv8-X | 68.2 | 257.8 | 53.9 (+1.0%) |
| YOLOv9-E | 58.1 | 192.5 | 55.6 (+2.7%) |
YOLO: the principle behind its high performance
YOLO is a fast and accurate algorithm for object detection because it uses a single convolutional neural network to predict the bounding boxes and class probabilities of the objects in an image.
- a bounding box is a rectangle that surrounds an object
- a class probability is a score that tells how likely the object belongs to a certain category, such as a person, a car, a dog, etc.
Unlike other methods that require scanning different parts one by one, YOLO only looks at the image once, which makes it much faster without compromising on accuracy. It divides the image into a grid of cells and selects the best bounding box for each object class.
However, YOLO also has some limitations, such as:
- it requires a large amount of labeled data for training
- it is sensitive to the choice of objective functions
- it loses information during the feature extraction and spatial transformation processes
While YOLOv7 made significant strides in optimizing training, it didn’t tackle the critical issue of information loss during data processing, a phenomenon known as the information bottleneck.
In the next chapter we’ll see how YOLOv9 tackles this.
YOLOv9 reduces the information loss
YOLOv9 solves the problem of information loss in deep learning models by using 2 new features: Programmable Gradient Information (PGI) and Generalized Efficient Layer Aggregation Network (GELAN).
Programmable Gradient Information (PGI)
PGI is a framework designed to improve the training process of deep learning models and address challenges faced by deep learning models in object detection, mainly information loss and error accumulation. The next figure illustrates how different methods and architectures manage information flow: (a) Path Aggregation Network (PAN)), (b) Reversible Columns (RevCol), (c) conventional deep supervision, and (d) Programmable Gradient Information (PGI).
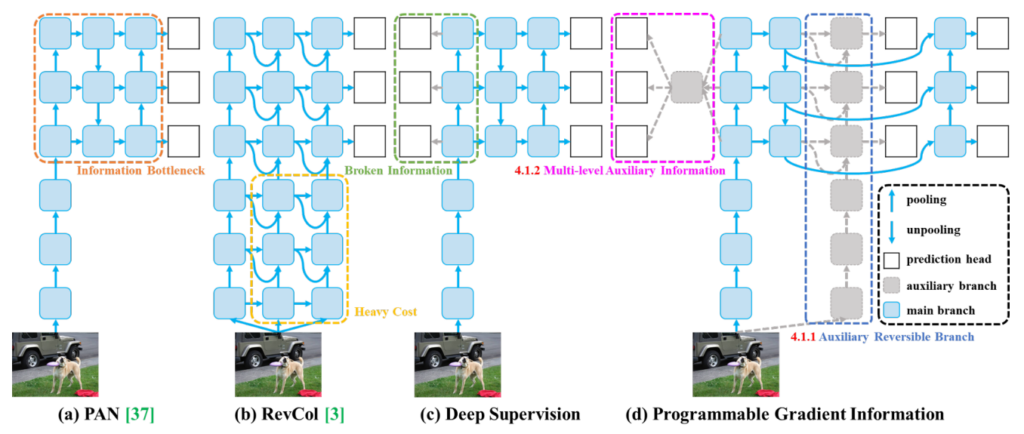
PGI incorporates three distinct but interconnected components:
- Main Branch 🠆 performs object detection quickly and accurately without any unnecessary calculations. It avoids using extra parts during prediction and keeps high speed without more computing cost.
- Auxiliary Reversible Branch 🠆 solves a big problem in deep neural networks: information loss. Information can be lost when networks get deeper and process layers one by one. This branch stops losing information by using a reversible architecture that makes gradients more trustworthy and parameter updates more accurate.
- Multi-Level Auxiliary Information 🠆 helps the model make better predictions for objects of different sizes by mitigating the information loss in early layers.
During training, deep learning models for object detection often use the shallow features extracted from the network’s early layers. These features primarily facilitate the detection of small objects, leading to the loss of information about larger objects.
To address this problem, the multi-level auxiliary information technique combines information about all target objects (with details of both small and large objects). This aggregated information is then sent to the main branch of the network that produces the final predictions. This way, the main branch can learn to generate accurate predictions for objects of different sizes.
Generalized Efficient Layer Aggregation Network (GELAN
YOLOv9 introduces GELAN, a new architecture that builds upon the principles used in YOLOv7’s ELAN (Efficient Layer Aggregation Network) but with greater flexibility and efficiency.
GELAN operates under two key principles:
- Gradient path planning: This ensures that essential information flows smoothly through the network, preventing loss during processing.
- Reversible functions: These functions allow the network to retain crucial details that might otherwise be discarded, contributing to more accurate results.
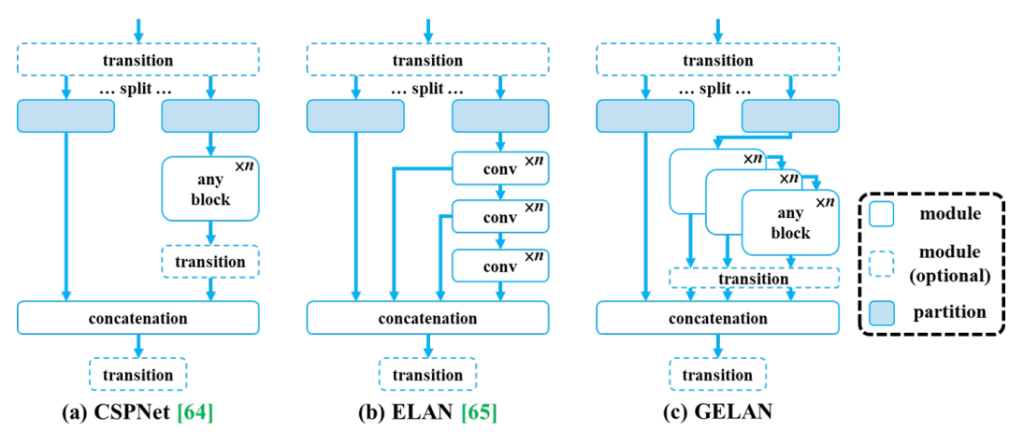
In essence, while PGI focuses on preserving information, GELAN focuses on efficiently utilizing that information within the YOLOv9 architecture for improved object detection performance.
Experiments
The proposed method was verified with the MS COCO dataset. All models were trained using the train-from-scratch strategy, and the total number of training times was 500 epochs. The table below shows YOLOv9 models.
| Model | Test Size | APval | AP50val | AP75val | Param. | FLOPs |
|---|---|---|---|---|---|---|
| YOLOv9-N (dev) | 640 | 38.3% | 53.1% | 41.3% | 2.0M | 7.7G |
| YOLOv9-S | 640 | 46.8% | 63.4% | 50.7% | 7.1M | 26.4G |
| YOLOv9-M | 640 | 51.4% | 68.1% | 56.1% | 20.0M | 76.3G |
| YOLOv9-C | 640 | 53.0% | 70.2% | 57.8% | 25.3M | 102.1G |
| YOLOv9-E | 640 | 55.6% | 72.8% | 60.6% | 57.3M | 189.0G |
They built general and extended version of YOLOv9 based on YOLOv7 and Dynamic YOLOv7 respectively and replaced ELAN with GELAN in the design of the network architecture.
Evaluation
YOLOv9’s performance was evaluated on MS COCO object detection dataset, against existing real-time object detection models trained from scratch. It surpassed previous methods in all aspects: parameters, computation, and accuracy (see the next picture).
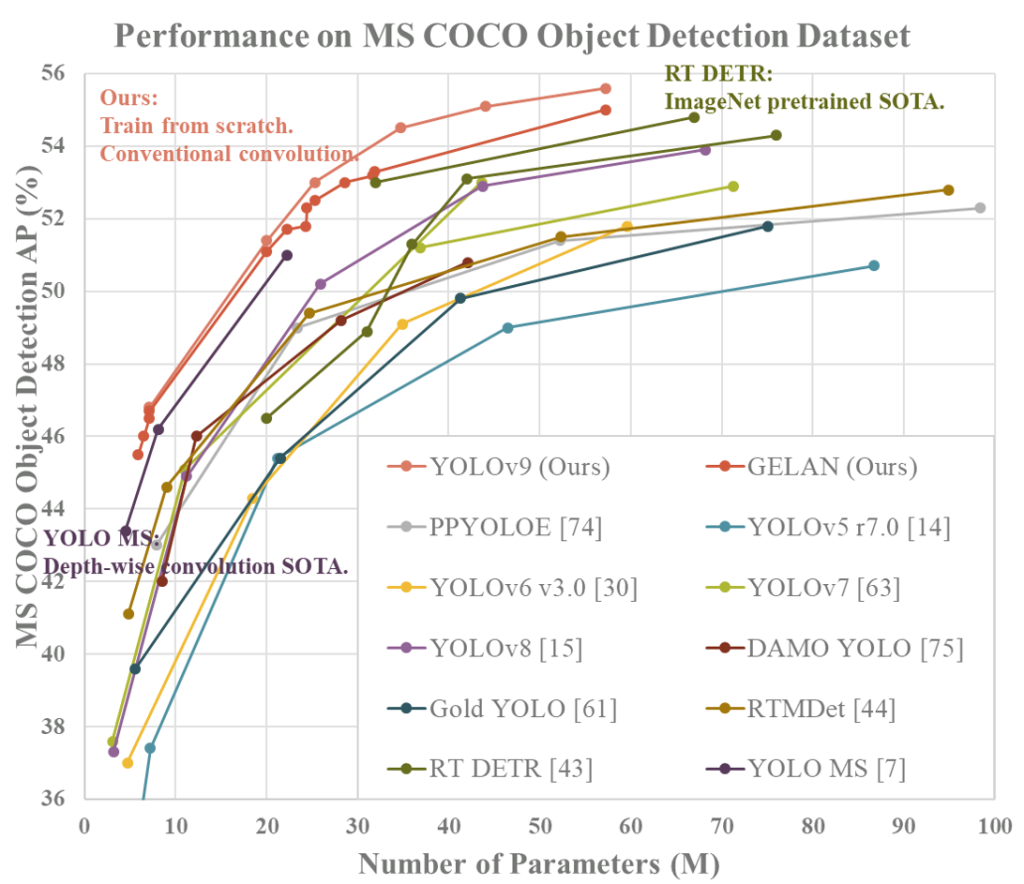
Compared to lightweight and medium models, YOLOv9 achieved higher accuracy with fewer parameters and reduced computation. Furthermore, YOLOv9 demonstrated exceptional parameter utilization even when compared to models leveraging pre-trained datasets like ImageNet.
Conclusion
YOLOv9 is a new version of YOLO that builds upon its predecessors and achieves remarkable efficiency and accuracy through its innovative architecture: PGI and GELAN. It can focus on the objects that are relevant for the target task and ignore the irrelevant ones.
Learn more:
- Research paper: “YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information” (on arXiv)
- “YOLOv9: Advancing the YOLO Legacy” (on LearnOpenCV)
- Repository






