
A new study from Google DeepMind reveals hidden reasoning abilities in large language models (LLMs). The new method called Chain-of-Thought-decoding (CoT-decoding) makes LLMs think more critically and solve problems better by following chains of thought. It doesn’t require extra prompts or explicit instructions.
How LLMs work
LLMs can produce natural language for diverse inputs, but they lack the ability to draw logical inferences due to their greedy decoding strategy that chooses the most likely next word at each step. They consider words one by one, picking the most “likely” next word based on what they’ve seen before.
While this approach leads to fluent and fast responses, it often neglects possible chains of thought (CoT) that could help LLMs reach a more rational outcome.
Previous research used special prompting techniques, such as few-shot or zero-shot CoT prompting, to make LLMs reason. But these methods require substantial human effort to create tailored prompts and are limited by the knowledge the LLMs were trained on.
LLMs show hidden reasoning skills
The new approach, CoT-decoding, unlocks the hidden reasoning abilities within LLMs. Unlike traditional methods that simply pick the most likely word next, CoT-decoding searches for CoT sequences of words that reveal the model’s internal logic.
The picture below showcases the power of this method: LLMs navigate through various “what-if” scenarios, each representing a potential outcome.
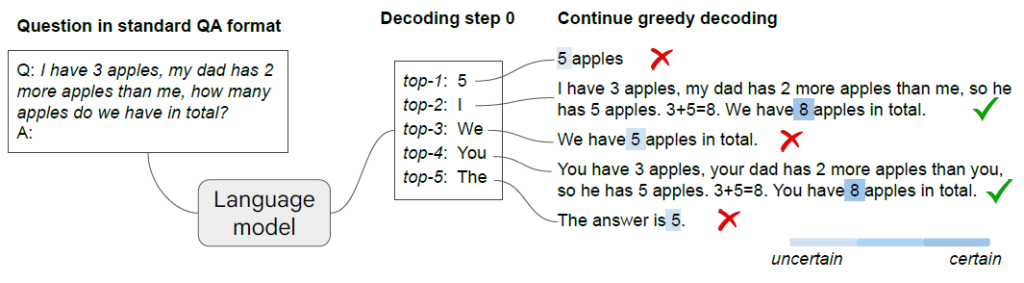
Here is an example of how the decoding process works with 9 different options. The model starts a “what-if” reasoning with a low-probability choice (k=9) and finds a CoT. The greedy strategy hides this scenario with the highest-probability choice (k=0).

How does CoT-decoding find these paths?
CoT-decoding uses a confidence score (Δ), which measures how confident the LLM is in each word choice. It calculates an average score (Δk) for each potential word path, by comparing the chances of the top two words at each step. A higher (Δk) score means a path that is more probable to be part of the final answer and show the model’s reasoning.
CoT-decoding looks at different choices at the first step, but when should it branch again? The next figure illustrates some examples of decoding paths with different branching points.

Early branching increases the variety of potential paths to go. However, if it chooses an incorrect token (“5”) in the initial steps, it will be difficult to find the correct path.
The best way to explore these paths depends on the problem the model tries to solve. For example, in the case of checking if a year is even or odd, mid-path branching helps it reach the correct answer.
CoT-decoding advantages
This method offers several potential advantages over traditional decoding methods for LLMs:
- Discovers hidden reasoning skills: unlike prompting, which explicitly guides the model towards a specific answer, CoT-decoding allows it to analyze multiple possible paths during decoding, unveiling reasoning capabilities.
- Reduces reliance on prompting: by automatically identifying CoT paths, CoT-decoding eliminates the need for manually crafted prompts.
- Improves accuracy: it leads to more accurate answers, particularly for tasks requiring deeper understanding and multi-step reasoning.
CoT-decoding may also be more time and memory consuming, as it tries out different possibilities in the decoding. These computational costs can be reduced by choosing a lower k or a smaller model.
Experiments and evaluation
The experiments aimed to explore how pre-trained models that have already learned from massive text datasets (like PaLM-2 and Mistral-7B) can reason like humans and generate answers.
The LLMs were tested for different tasks that require the model to use logic, knowledge, and calculation skills, such as (I) Mathematical reasoning, (II) Natural language reasoning and (III) Symbolic reasoning:
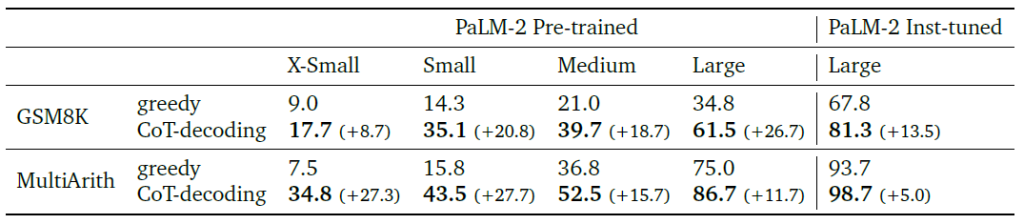
I. Mathematical reasoning. To test how CoT-decoding enhances mathematical reasoning abilities, they evaluated it on two math datasets – GSM8K and MultiArith. As the table below demonstrates, CoT-decoding consistently outperforms greedy decoding across various PaLM-2 model sizes, showcasing its ability to improve mathematical reasoning in large language models.
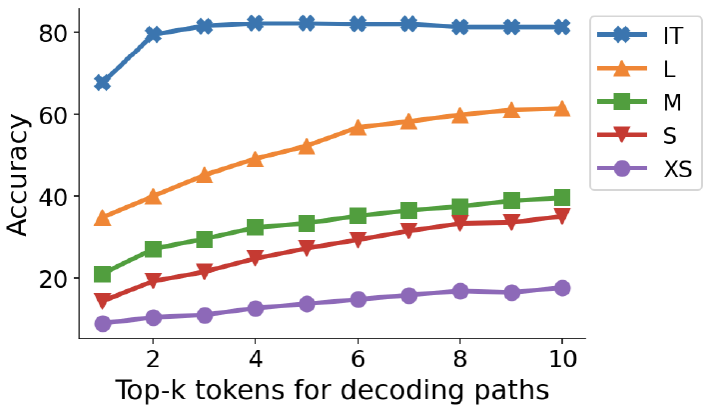
Considering more alternative starting words (k) affects the model’s accuracy (see the picture below). Generally, the higher the k, the better the model performs. This suggests that the correct reasoning paths might exist but are often ranked lower during the greedy decoding process.
Interestingly, for models that received additional instruction-tuning to learn reasoning steps, the impact of k is smaller. This indicates that instruction-tuning leads to better performance even with lower k values.
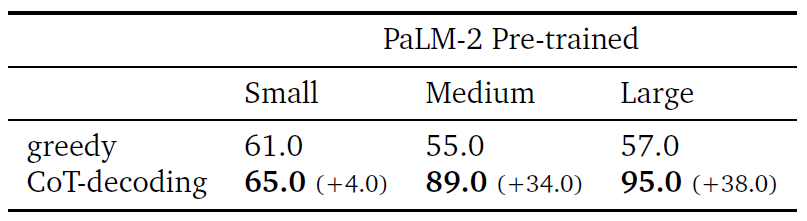
II. Natural language reasoning. The researchers tested CoT-decoding on the “year parity” task, where the model has to answer whether a celebrity was born in an even or odd year. The results showed that while most models struggle with this task when asked directly, CoT-decoding helped them uncover the correct CoT paths and improve their accuracy.
III. Symbolic reasoning. They investigated the symbolic reasoning capabilities of LLMs) through three symbolic tasks: coin flip, web of lies, and multi-step arithmetic, with different difficulty levels.
CoT-decoding consistently outperformed the standard greedy approach across all tasks. This suggests that LLMs possess intrinsic symbolic reasoning abilities, further enhanced by specific decoding strategies like CoT-decoding.
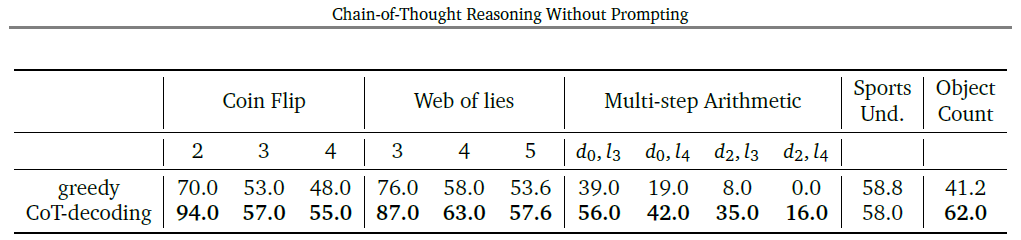
The overall evaluation results demonstrate that CoT-decoding outperforms the standard greedy decoding on various reasoning benchmarks.
There is also a correlation between the presence of a CoT in the decoding path and the model’s confidence in its answer.
Conclusion
The study shows that CoT reasoning doesn’t need explicit prompting or specific instructions. It can be drawn out from LLMs by using special decoding methods, such as CoT-decoding.
This leads to new possibilities for future research on the reasoning capabilities of LLMs, allowing for more natural interactions with them.
Learn more:
Research paper: “Chain-of-Thought Reasoning Without Prompting” (on arXiv)






