
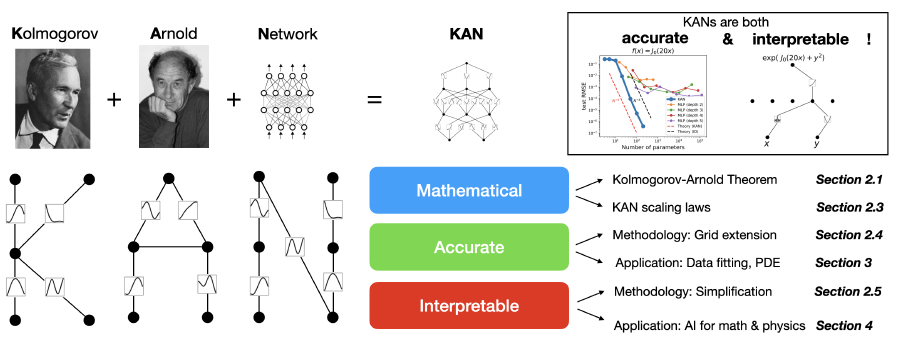
Kolmogorov-Arnold Networks (KANs) represent a new neural network architecture where the connections between neurons are able to independently learn their own activation functions. This is a significant shift from the traditional approach where neurons have fixed activation functions. The inherent flexibility of KANs enables them to learn and adapt better than the conventional Multi-Layer Perceptrons (MLPs), being more accurate for various tasks.
KANs require significantly fewer parameters to achieve comparable or even better accuracy than MLPs on tasks like data fitting and solving partial differential equations (PDEs). This translates to faster training times and reduced computational resources.
In KANs, the activation functions are placed on the edges (connections) between nodes and are designed to be learnable. They can adapt their shape in response to the input data, allowing for a more dynamic and flexible learning process. This key feature enables KANs to potentially model complex patterns more effectively than MLPs, which rely on static weights and predefined activation functions.
How to use KANs
The authors created pykan, an open-source implementation for KANs. The repository provides an installation guide and many Notebook tutorials and examples.
For a comprehensive understanding of KAN, you can start with the official documentation that offers a detailed exploration of KANs, including the mathematical foundations, how to get started, API details and demos, and practical examples.
The Kolmogorov-Arnold representation theorem
The Kolmogorov-Arnold representation theorem states that any function with multiple variables (multivariate function), including a neural network’s output, can be expressed as a combination of simpler functions that depend on a single variable (univariate functions).
In simpler words, it suggests that you can recreate any complex multivariate function by either adding a finite number of these univariate functions together or feeding the output of one function into another.
In the context of neural networks, this theorem demonstrates that the output of a network, no matter its complexity, can be represented as a combination of simpler functions. This leads to more efficient and interpretable neural network designs.
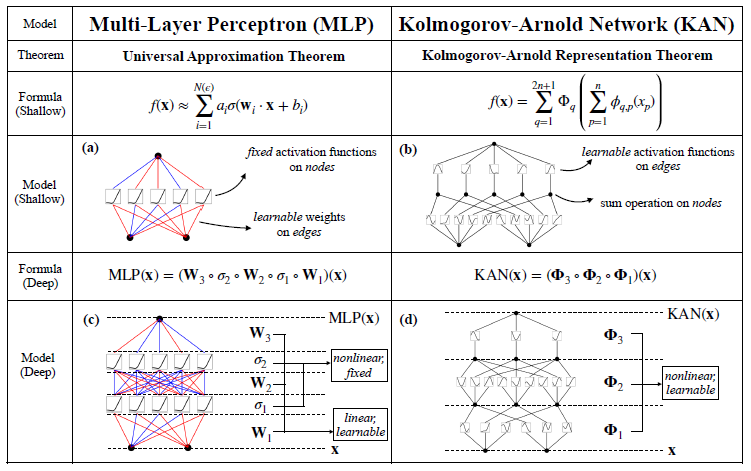
Traditional neural networks vs KAN
Traditional neural networks learn by adjusting weights, which are numerical values that determine the strength of the connection between neurons. During the training process, the network adjusts these weights to minimize the error between its predictions and the actual outcomes.
In contrast, KANs are designed to learn functions. Instead of merely adjusting numerical weights, KANs identify and adapt the specific univariate functions. KANs replace the static weight parameters of MLPs with dynamic, learnable functions that are capable of adapting their shape to better capture the relationships in the data.
The picture below shows a KAN neural network that dynamically adapts its activation functions to better capture the complexities of the data it is learning from. It’s a more advanced and flexible method compared to traditional neural networks, which typically use fixed activation functions.
- Left: the activation signals that move through the network. These signals are the neuron outputs after applying the activation function and serve as the inputs for the following neurons.
- Right: the activation function is defined using a B-spline (a type of polynomial function).
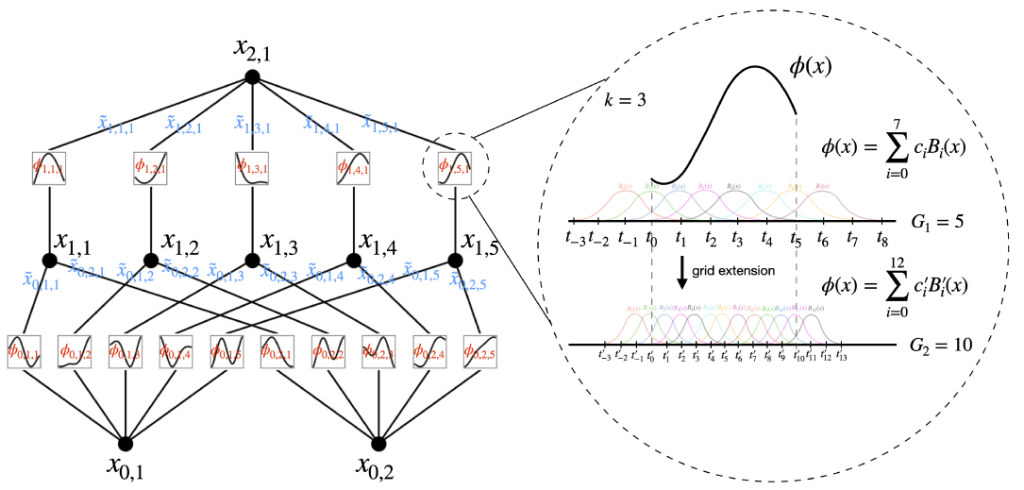
The key difference is that traditional neural networks focus on finding the right values (weights) within a fixed structure, whereas KANs focus on discovering the right structure (functions) itself. This enables KANs to potentially identify more complex patterns with greater efficiency and clarity. It marks a transition from learning static numbers to learning dynamic, functional forms that can better reflect the complexities of the data they represent.
In conclusion, while traditional neural networks come with predefined activation functions and learn the weights, KANs operate by taking predetermined weights and learning the activation functions.
The table below outlines the main differences between KANs and MLPs.
| Feature | MLPs | KANs |
|---|---|---|
| Activation functions | Fixed on nodes (neurons) | Learnable on edges (weights) |
| Weights | Linear weights | Spline functions (non-linear weights) |
| Accuracy (Data Fitting/PDE Solving) | Smaller KANs can achieve comparable or better accuracy than much larger MLPs | Larger MLPs may be needed for comparable accuracy |
| Scaling | Slower scaling | Faster scaling |
| Interpretability | Complex, difficult to visualize | Intuitive visualization, easier to understand |
| Applications | Widely used in deep learning models, but may lack interpretability and require larger models for certain tasks | Shown to be useful collaborators in mathematics and physics, aiding in (re)discovering laws |
| Potential | Established as the primary architecture in deep learning, but may face challenges in interpretability and scalability | Promising alternatives for MLPs, opening opportunities for further improvement in deep learning models |
Training
The architecture of KANs is designed to be differentiable, which is an essential property that allows the use of standard backpropagation techniques for training. The network learns its own activation functions, thus achieving greater accuracy in performing tasks such as classification and regression. Furthermore, the activation functions that KANs learn provide valuable insights into the network’s decision-making process, thereby enhancing interpretability.
Evaluation
The empirical evaluation has shown that KANs are proficient in data fitting and solving PDEs. Smaller KANs can achieve comparable or even better accuracy than much larger MLPs in these tasks. Specifically, for PDE solving, a 2-layer width-10 KAN is 100 times more accurate than a 4-layer width-100 MLP, and also 100 times more efficient in terms of the number of parameters required.
KANs can be intuitively visualized, making it easier for human users to understand and interpret the model’s decisions. Since KANs use learnable functions on their connections, scientists can observe how these individual functions contribute to the final output. This transparency allows them to understand the reasoning behind the KAN’s answer and identify any potential biases or errors that may exist within the model.
Applications
The authors demonstrate, using two examples, the way in which KANs can assist scientists in (re)discovering mathematical and physical laws:
- In Knot theory, which deals with understanding complex shapes in 3D and 4D spaces, KANs can identify the invariant properties of knots. These properties remain unchanged even when the knot is manipulated. KANs’ ability to identify these knot features, outperforming traditional methods like MLPs.
- In Anderson localization, a phenomenon in physics where electrons get trapped in disordered materials, KANs can help understand the conditions leading to this trapping and identify patterns or rules that govern the behavior of electrons in these systems.
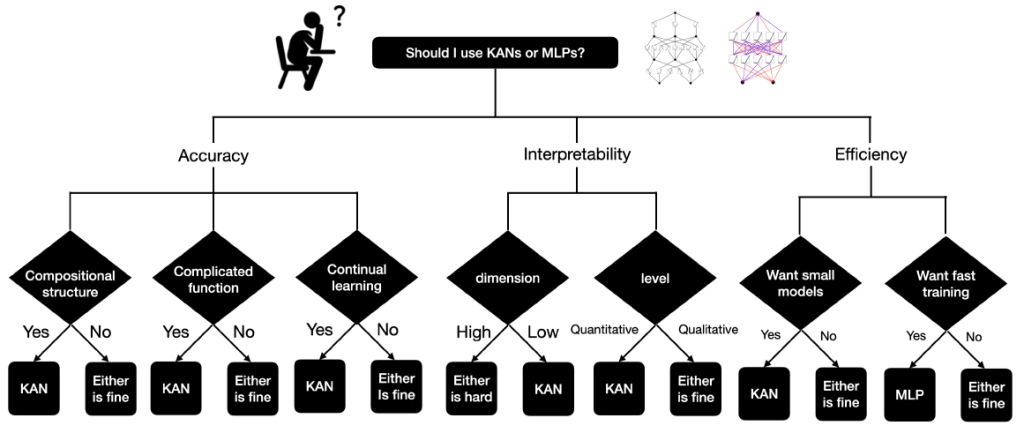
Should we use KANs or MLPs?
At present, the primary challenge with KANs is their prolonged training time. They tend to train about 10 times slower than MLPs with an equivalent number of parameters. The slow training pace of KANs is considered a technical issue that can be addressed in future developments.The next flowchart helps you decide between KANs and MLPs.
Conclusion
KANs represent a significant step forward in neural network architecture. Their ability to learn activation functions increase the accuracy and interpretability of neural networks.
However, training KANs can be computationally expensive compared to MLPs, requiring further optimization techniques.
Read more:
- Paper on arXiv: “KAN: Kolmogorov-Arnold Networks”
- GitHub repository (official implementation for KANs)
- Documentation
- Awesome KAN (a curated list of libraries, tutorials, papers, and other resources related to KANs)






