
OOTDiffusion (Outfitting over Try-on Diffusion) is an innovative model for image-based virtual try-on (VTON). It leverages the latent diffusion models (LDMs) to generate realistic images while preserving intricate garment details.
The model was proposed by a research team from Xiao-i, a cognitive intelligence company from Shanghai founded in 2001. It is open-source and can be accessed here.
OOTDiffusion achieves natural garment fits on various body shapes and offers greater user control than previous approaches over the virtual try-on experience.
The figure below shows the results of a cross-dataset evaluation of different models that were trained on the VITON-HD dataset and tested on the Dress Code dataset. OOTDiffusion generates more realistic outfitted images and preserves many more garment details.

The virtual try-on (VTON) technology has improved the online shopping experience and lowered the advertising cost for the e-commerce industry. It enables users to see how they look in different garments, avoiding the uncertainty related to size and fashion. However, current VTON methods struggle to achieve high realism, maintain garment details, and guarantee a natural fit for various body types and poses.
Different methods have been explored for virtual try-on (VTON), such as Generative Adversarial Networks (GANs) and Latent Diffusion Models (LDMs), such as TryOnDiffusion. They both encounter difficulties when representing intricate details like text, textures, and patterns on clothing.
- The training process in GANs can be unstable, leading to blurry or distorted representations of garments.
- Traditional LDM-based methods often rely on the warping techniques to fit the garment onto the person’s image. This approach can lead to unnatural-looking results where the garment appears “pasted” onto the body and intricate details might be lost.
OOTDiffusion addresses these limitations by introducing a novel architecture that leverages the strengths of LDMs while overcoming the issues associated with warping techniques.
Model
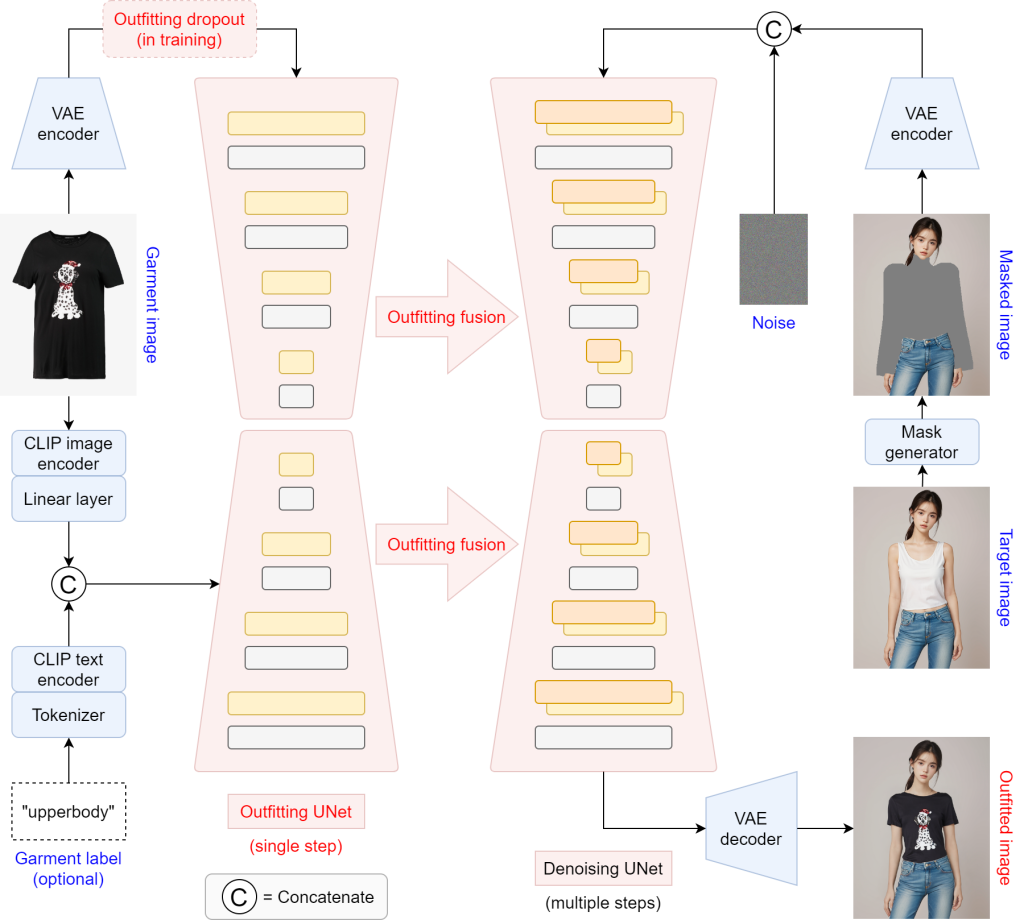
The OOTDiffusion model leverages the pre-trained LDMs and incorporates the following key elements to enhance the quality of the generated images:
- Outfitting UNet learns garment details (style, material properties, and intricate patterns) in a single step. This is a custom neural network designed specifically for OOTDiffusion. It analyzes an image of the garment and extracts its key details in the latent space (a lower-dimensional representation of the image). The outfitting UNet is similar to the denoising UNet of Stable Diffusion.
- Outfitting Fusion correlates the garment features with the target human body seamlessly, bypassing a separate warping step.
- Outfitting dropout is employed during training to enhance controllability, allowing for conditional and unconditional training of the denoising UNet.
OOTDiffusion’s pipeline begins by taking a picture of a person and an image of clothing. It isolates the person in a masked image, compresses it with a VAE encoder, and injects Gaussian noise. A denoising UNet cleans the image, while an outfitting UNet learns and applies the garment’s details. These details are then fused with the denoised image of the person, resulting in a composite image.
Finally, a VAE decoder refines this image, delivering a high-quality virtual try-on that seamlessly integrates the garment with the human figure, all without traditional warping techniques.
Experiments
The experiments were performed on two high-resolution (1024 × 768) virtual try-on datasets, i.e., VITON-HD and Dress Code. OOTDiffusion was compared with multiple state-of-the-art VTON methods. The evaluation focuses on the visual quality and realism of the generated outputs, assessing their fidelity to the input garments and the target person’s pose.
The qualitative evaluation indicates that OOTDiffusion surpasses other virtual try-on methods. OOTDiffusion consistently achieves the best try-on effects for various upper-body garments, while the GAN-based methods like GP-VTON often fail to generate realistic fitting clothes.

upper-body garments (source: paper)
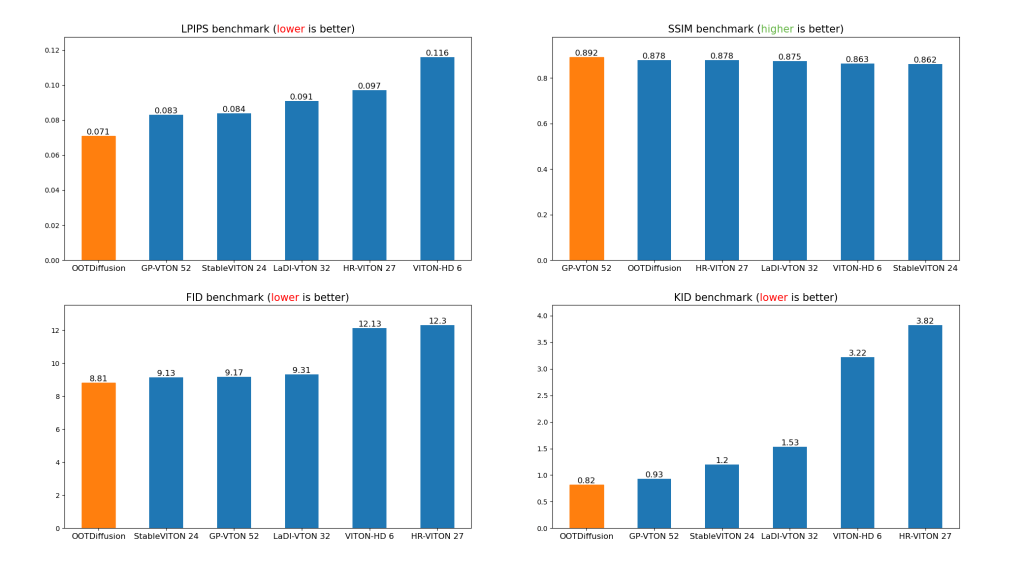
For the quantitative evaluation, OOTDiffusion was tested at a resolution of 512 × 384, even though it can support higher resolutions up to 1024 × 768. This was done to ensure a fair and consistent comparison with previous virtual try-on (VTON) methods. Some of the results are presented in the following chart. The metrics LPIPS, SSIM, FID, and KID are used to evaluate the quality of images generated by the model.
Benefits of OOTDiffusion’s approach
- Smooth adaptation: by avoiding warping, OOTDiffusion ensures smoother adaptation of the garment to different body types. This eliminates the risk of information loss or distorted features that can occur with warping techniques.
- Controllable garment features: the outfitting dropout process introduces an additional layer of control. During training, a small portion of the extracted garment features are randomly dropped, helping the model learn more robust representations. Additionally, it provides users with a guidance scale (garment label, such as “upperbody”), allowing for a more personalized and controlled try-on session.
Despite its advanced capabilities, the model faces two main limitations. Firstly, it encounters difficulties with cross-category try-ons due to its training on specific paired images. Secondly, it may unintentionally alter original human image details, such as muscles, because these areas are masked and repainted by the diffusion model. Future research might address these limitations.
Conclusion
OOTDiffusion eliminates the need for explicit warping by integrating garment details directly in the latent space during the image generation process.
If you have ever wondered how you would look in a different outfit without actually trying it on or if you have ever wanted to create your own fashion style by mixing and matching different garments, you might be interested in the open source OOTDiffusion model. It can generate realistic images of you wearing any garment you choose.






