
GenericAgent (code, paper) is a self-evolving LLM‑powered agent framework capable of controlling your entire computer.
The system uses a minimal set of atomic tools to perform tasks such as web browsing, filesystem manipulation, code execution, keyboard and mouse control, and screen perception through vision capabilities. It can also interact with mobile devices via Android’s ADB interface.
GenericAgent (GA) is fully open‑source and can be accessed here. In evaluations, it consistently outperforms leading agent systems like Claude Code, OpenAI Codex, and OpenClaw, all while consuming fewer tokens and completing tasks in fewer steps.
The agent automatically continues to optimize over time through a self-evolving mechanism. When you give it a new task, GenericAgent solves it step-by-step and saves those steps as a new skill. The more you use it, the more skills it collects, growing into your personal library of skills that are custom-made for the way you work.
Key features
- Self-evolving: Converts each completed task into a reusable skill.
- Minimal architecture: Contains around 3,000 lines of code. The main agent loop is only about 100 lines long.
- Browser-integrated control: Can operate directly within a real web browser while keeping login sessions active. It uses a set of 9 simple tools to control and interact with the system effectively.
- Token efficiency: Uses less than 30,000 tokens for its context window, which is much smaller compared to the 200,000 to 1M tokens used by many other agents.
The context overload problem in AI agents
Traditional LLM agents struggle with long interactions. As conversations or tasks grow, they accumulate tool outputs, memory, and environmental feedback. This leads to context overload, where critical information gets buried or even lost.
A good AI agent needs enough information to understand the task, but not so much that it becomes overloaded. If the context is too complete, it may contain too much unnecessary information, making the agent slow and confused. If the context is too concise, important details may be missing, leading to mistakes or poor decisions (see the picture below).
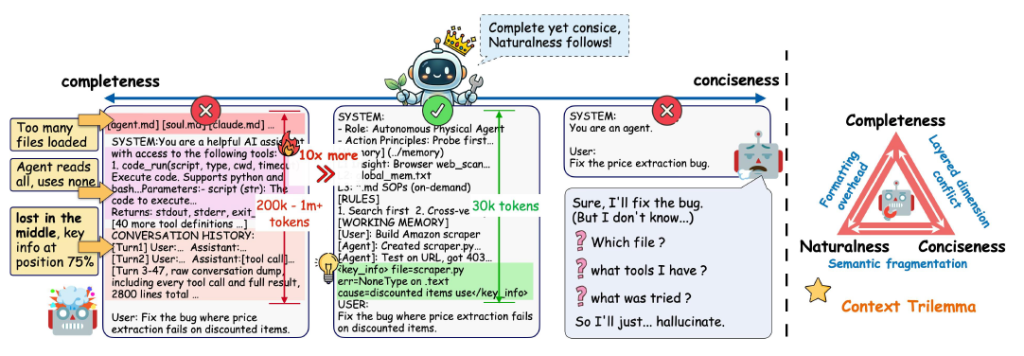
GenericAgent keeps the right balance between completeness and conciseness because its entire architecture is built around minimal atomic tools, self‑evolving skills, and LLM‑driven planning that avoids unnecessary steps.
The model
GenericAgent is a framework built around existing LLMs. It can integrate with models such as Claude, Gemini, and other major LLM APIs. The system consists of four tightly integrated modules: a minimal tool set, hierarchical memory, self-evolution layer, and structured browser extraction.
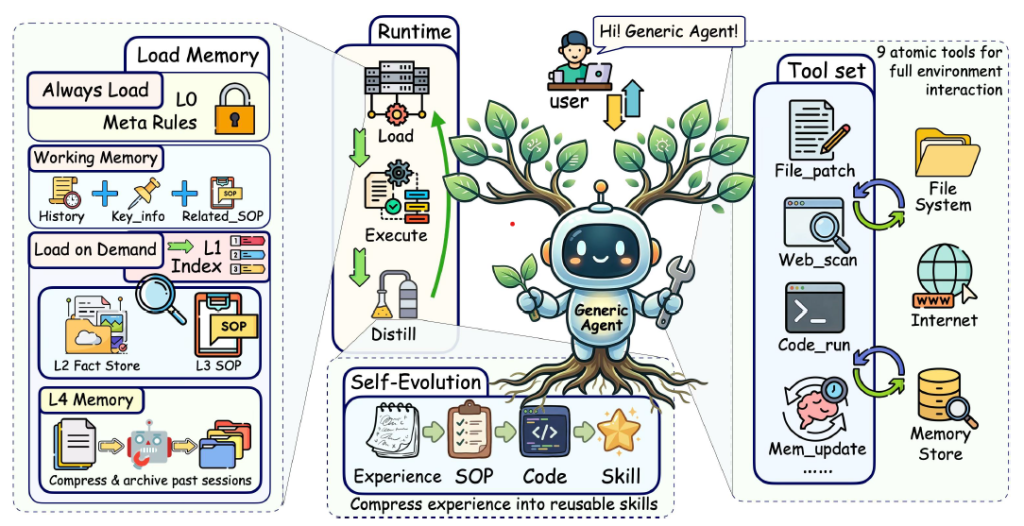
A minimal tool set: To keep GA incredibly small (~3K lines of code), the agent avoids having a specific app for every task. Instead, it uses 9 atomic tools for browser control, filesystem operations, screen vision, keyboard/mouse input, code execution, and ADB for mobile. Because they are composable, the agent can express any complex workflow without needing dozens of specialized APIs.
Hierarchical memory: GA uses a structured memory system to keep its workspace organized and efficient. In many other AI systems, every past action and detail stays in the active memory. Over time, this creates a clutter of old data that confuses the AI and makes it harder for it to think clearly or make good decisions. To solve this, GA organizes memory into 2 levels:
- The Always-On Layer: This is a very small, permanent part of the AI’s memory. It does not store every detail; instead, it acts like a simple map or index that tells the AI what information is available.
- The Deep Memory Layers: All detailed records, past steps, and complex facts are compressed and stored in the “back” of the system. This information stays hidden until the AI specifically needs it.
When it learns something new, GA creates a very short summary to keep in the Always-On Layer. When it needs the full details later, it uses that summary as a pointer to pull the exact information it needs from the Deep Memory Layers.
Self-evolution layer: This is a mechanism designed to transform successful task execution into permanent operational knowledge. After the successful completion of a complex task, the agent takes the optimal execution path, filters out situational noise, such as errors or temporary workarounds, and extracts a refined, reusable skill. These refined skills are stored within a local Skill Tree to be further reused for other similar tasks. Past interaction histories are transformed into reusable Standard Operating Procedures (SOPs) and executable code.
Structured browser extraction: This is one of the most powerful features of GA. While traditional web tools often struggle to read websites correctly, GA navigates a website and converts raw, unstructured HTML into organized, machine-readable data, such as a table or JSON. Instead of you spending hours copying and pasting data into a spreadsheet, the agent can do it for you. It can visit multiple websites, find the specific facts you need, and present them in a perfect, easy-to-read format.
The next table showcases the self-evolution mechanism:
| Task | What the agent does the first time | What was learned after |
|---|---|---|
| WeChat “Read my WeChat messages” | Install deps (dependencies) → reverse DB (figures out how to talk to the apps on your computer, like finding where WeChat stores messages) → write read script → save skill | How to decrypt and read the local database. |
| Stocks “Monitor stocks and alert me” | Install mootdx (downloads the necessary libraries for stocks)→ build selection flow → configure cron (setting up a digital alarm clock) → save skill | How to use specific financial libraries and set a schedule (cron). |
| Gmail “Send this file via Gmail” | Configure OAuth → write send script → save skill | How to handle secure logins (OAuth) and file attachments. |
As it completes tasks, the model turns those experiences into reusable skills, forming a skill tree that will be used in future sessions.
Advantages of using GenericAgent
- Reduced computational cost
- Faster execution
- Better scalability
The most significant data point is the 7x reduction in token consumption, compared to Claude Code, OpenAI Codex, and OpenClaw. In standardized benchmarks, GenericAgent completed the same task suite as OpenClaw using 3.9M tokens, compared to 27.3M for OpenClaw.
This is largely due to its contextual information density design, which keeps the active conversation much smaller (often under 30K tokens) than competitors that can use up to 200K+ tokens, whereas other agents may expand to 100K–200K+ during long workflows.
The table below shows the main differences between GA, Claude Code, OpenAI Codex, and OpenClaw.
| Feature | GenericAgent | Claude Code / Codex | OpenClaw |
|---|---|---|---|
| Focus | General computer use + self-evolution | Specialized coding & repo management | Visual-based computer interaction |
| Code Size | ~3K lines (Minimalist) | Large / Proprietary | ~530K lines (Complex) |
| Learning | Saves custom “Skill Trees” | Fixed capability sets | Mostly session-based |
| Memory | Hierarchical / Compressed | Context-compaction | Persistent but can be noisy |
While GenericAgent is designed for general computer use, allowing an AI to operate a full desktop environment and gradually improve its abilities, Claude Code and Codex focus mainly on software development tasks and OpenClaw emphasizes vision‑based interaction, enabling an agent to control a computer by interpreting what appears on the screen.
Evaluation
GenericAgent was evaluated across five main areas: task completion, token efficiency, tool usage, memory effectiveness, self-evolution, and web browsing performance. The tests measured how efficiently the agent completes the tasks, manages memory, uses its minimal toolset, learns from past interactions by creating reusable procedures and code, and handles complex web-based tasks in dynamic environments.
The table below illustrates the task completion rate and token efficiency across the main agent benchmarks and RealFin-benchmark. GA shows consistent performance across all three benchmarks.
| Benchmark | Agent | Model | Accuracy | Input Tokens | Output Tokens | Total Tokens | Efficiency |
|---|---|---|---|---|---|---|---|
| SOP-Bench | GA | Claude Sonnet 4.6 | 100% | 2.02M | 53k | 2.08M | 0.48 |
| OpenClaw | Claude Sonnet 4.6 | 100% | 2.60M | 40k | 2.64M | 0.38 | |
| Claude Code | Claude Sonnet 4.6 | 85% | 1.23M | 23k | 1.25M | 0.68 | |
| GA | Minimax M2.7 | 90% | 893k | 32k | 924k | 0.97 | |
| OpenClaw | Minimax M2.7 | 95% | 2.91M | 46k | 2.96M | 0.32 | |
| Lifelong AgentBench | GA | Claude Sonnet 4.6 | 100% | 222k | 20k | 241k | 4.15 |
| OpenClaw | Claude Sonnet 4.6 | 70% | 1.43M | 21k | 1.45M | 0.48 | |
| Claude Code | Claude Sonnet 4.6 | 75% | 800k | 14k | 814k | 0.92 | |
| GA | Minimax M2.7 | 90% | 400k | 23k | 423k | 2.12 | |
| OpenClaw | Minimax M2.7 | 70% | 1.20M | 17k | 1.22M | 0.57 | |
| RealFin-benchmark | GA | Claude Sonnet 4.6 | 65% | 102k | 12k | 114k | 5.70 |
| Claude Code | Claude Opus 4.6 | 60% | 290k | 17k | 307k | 1.95 | |
| Claude Code | Claude Sonnet 4.6 | 55% | 226k | 12k | 238k | 2.31 | |
| OpenClaw | Claude Sonnet 4.6 | 35% | 249k | 2k | 251k | 1.39 | |
| Codex | GPT-5.4 | 60% | 838k | 54k | 892k | 0.67 |
The next table shows the results for long-horizon, complex tasks. The evaluation includes 5 categories: document generation (PDF/PPT creation), SQL copilot query generation, experiment analysis report writing, procurement decision-making with web retrieval, and feasibility analysis for reproducing research papers. The table summarizes the average performance across the full set of long-horizon tasks.
| Agent | # Tasks | Success | Total Tokens | Time (s) | Requests | Tool Calls |
| Claude Code | 5 | 100.0% | 537,413 | 320.8 | 32.6 | 22.6 |
| GenericAgent | 5 | 100.0% | 188,829 | 220.8 | 11.0 | 12.8 |
| OpenClaw | 5 | 80.0% | 633,101 | 183.1 | 15.0 | 16.6 |
We can see that GenericAgent is the most balanced agent. It matches the perfect accuracy of the best models but does so faster, with fewer requests, and at a fraction of the cost. GenericAgent only used 188,829 tokens, while Claude Code used over 537,000 tokens and OpenClaw used over 633,000 tokens. This means that GenericAgent is nearly 3x cheaper to run than Claude Code and 3.34x cheaper than OpenClaw.
We observe that GenericAgent is the most balanced agent, achieving performance comparable to the best-performing models while requiring significantly fewer resources. It maintains top-level accuracy while operating with fewer requests, faster execution, and substantially lower token usage. Specifically, GenericAgent uses only 188,829 tokens, compared to over 537,000 tokens for Claude Code and over 633,000 tokens for OpenClaw. This corresponds to approximately 2.8× lower token usage than Claude Code and 3.3× lower than OpenClaw.
The table below shows prompt length after adding 20 skills under intensive usage with minimal input. GenericAgent (GA) prevents uncontrolled context growth.
| System | Full Prompt Length (tokens) |
| OpenClaw | 43,321 |
| CodeX | 23,932 |
| Claude Code | 22,821 |
| GenericAgent | 2,298 |
Quick start guide to GenericAgent
Follow the installation steps in the GitHub repository. In summary, there are two install methods:
- run a one-line command that downloads and executes an install script
- git-clone the repository and install the Python dependencies
Afterwards, you must to set your LLM API key by editing the “mykey.py” file. It supports OpenAI-compatible APIs and Anthropic Claude native APIs.
Finally, you can launch one of the frontends specified in the README. You have these choices: a desktop GUI, a terminal UI and a Streamlit UI.
Conclusion
GenericAgent represents a significant departure from the bigger is better trend in AI development. While the industry often achieves performance through massive context windows and complex, multi-agent orchestrations, GA proves that a minimalist seed architecture can be more effective, efficient, and adaptable.
By reducing the system prompt by 90% and relying on just 9 atomic tools, GA avoids the complexity of traditional automation.
The agent’s true strength is its Self-Evolution Layer, which distills complex, trial-and-error interactions into permanent, executable SOPs. The agent becomes faster, cheaper, and more personalized with every task it completes.





